Wer kennt das nicht? Du sitzt spät abends vor deinem Rechner, die Deadline drückt und plötzlich wirft Git eine Fehlermeldung aus, die dir den Schweiß auf die Stirne treibt. Du wolltest doch nur ein Git Pull From A Remote Branch durchführen, um den neuesten Stand deiner Kollegen zu sichern. Statt der erwarteten Aktualisierung landest du in einem Chaos aus Merge-Konflikten oder Fehlermeldungen über "diverging branches". Das Problem ist oft nicht das Werkzeug selbst, sondern ein grundlegendes Missverständnis darüber, wie Git Daten zwischen deinem lokalen Rechner und dem Server bewegt. Git ist kein einfaches Kopierprogramm, sondern ein System zur Verwaltung von Historien. Wer das begreift, spart sich Stunden voller Frust und vermeidet kaputte Repositories.
Die Mechanik hinter dem Abrufen von Daten
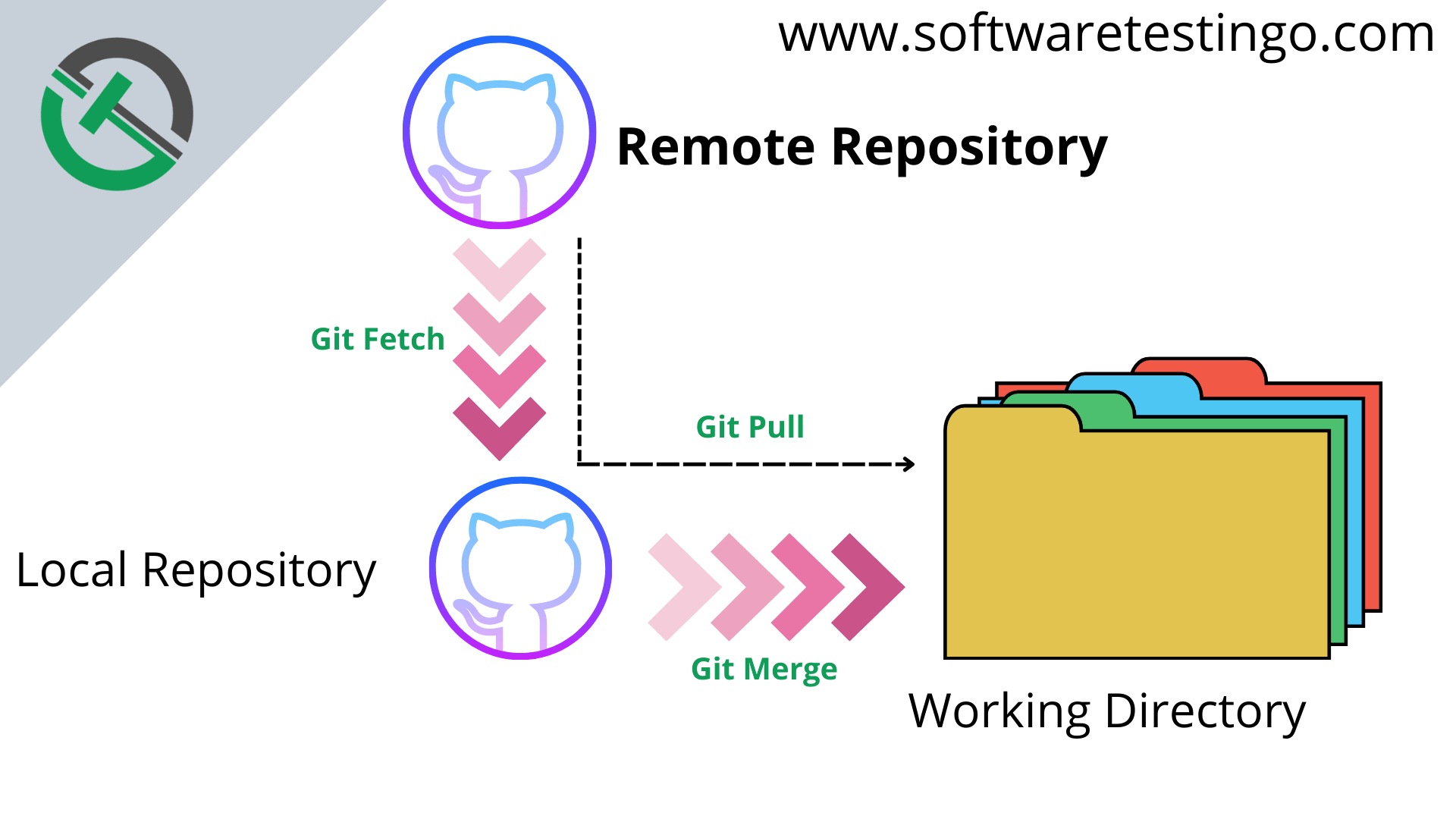
Bevor wir uns die Befehle im Detail anschauen, müssen wir klären, was im Hintergrund passiert. Ein Abrufvorgang ist eigentlich eine Kombination aus zwei verschiedenen Schritten. Zuerst holt Git die Daten vom Server. Das ist der Teil, den man oft manuell mit einem Fetch erledigt. Im zweiten Schritt versucht Git, diese neuen Informationen in deinen aktuellen Arbeitsstand zu integrieren. Wenn Leute über die Synchronisation sprechen, meinen sie meistens diesen kombinierten Prozess.
Das Herzstück der Zusammenarbeit ist die Verknüpfung zwischen deinem lokalen Speicherort und dem entfernten Server, meist "origin" genannt. Wenn du ein Projekt klonst, legt Git diese Verbindung automatisch an. Aber was passiert, wenn ein Kollege einen neuen Zweig erstellt hat, den du lokal noch gar nicht kennst? Hier scheitern viele Anfänger. Sie versuchen, auf einen Stand zuzugreifen, von dem ihr lokales System noch nichts weiß. Du musst deinem System erst beibringen, dass es diesen neuen Pfad auf dem Server gibt.
Der Unterschied zwischen Fetch und Pull
Ich sehe immer wieder, dass Entwickler diese beiden Begriffe synonym verwenden. Das ist ein Fehler. Ein Fetch ist absolut sicher. Er lädt nur die Metadaten und die neuen Commits herunter, verändert aber nichts an deinem aktuellen Code. Du kannst dir das wie das Herunterladen einer Zeitung vorstellen: Du hast sie zwar im Haus, aber du hast die Informationen darin noch nicht in dein Handeln übernommen.
Der eigentliche Zusammenführungsprozess hingegen ist der Moment, in dem es brenzlig wird. Hier entscheidet Git, wie die fremden Änderungen mit deinen eigenen kombiniert werden. Standardmäßig geschieht dies durch einen Merge-Commit. Das führt oft zu diesen unschönen "Merge branch 'xyz' of..." Nachrichten in der Historie, die kein Mensch lesen will. Es gibt bessere Wege, aber dafür muss man verstehen, wie man die Werkzeuge präzise steuert.
Warum Tracking Branches wichtig sind
Ein oft übersehenes Konzept sind die sogenannten Tracking Branches. Das sind lokale Zweige, die eine direkte Verbindung zu einem Pendant auf dem Server haben. Wenn du einfach nur einen Befehl tippst, ohne Namen zu nennen, schaut Git in der Konfiguration nach: "Ist dieser lokale Zweig mit einem entfernten verknüpft?" Wenn ja, weiß Git genau, woher die Daten kommen sollen. Wenn nein, kommt die berüchtigte Fehlermeldung, dass keine Upstream-Informationen gefunden wurden. Du kannst diese Verknüpfung jederzeit manuell mit dem Flag --set-upstream herstellen. Das ist besonders nützlich, wenn du ein Feature lokal startest und es erst später auf den Server schiebst.
Git Pull From A Remote Branch in der täglichen Praxis
Es gibt Situationen, in denen du gezielt einen Stand von einem anderen Zweig holen willst, der nicht dein aktueller ist. Stell dir vor, du arbeitest an einem Bugfix, aber die Basis dafür liegt auf einem speziellen Entwicklungszweig des Teams. In diesem Fall musst du explizit angeben, woher die Daten kommen sollen. Die Syntax ist hierbei entscheidend. Du nennst erst den Remote-Namen und dann den Namen des Zweigs auf dem Server.
Ein häufiger Stolperstein ist die Annahme, dass Git automatisch weiß, welcher lokale Zweig aktualisiert werden soll. Wenn du dich auf Zweig A befindest und versuchst, Daten für Zweig B zu ziehen, wird Git versuchen, die Änderungen von B in deinen aktuellen Zweig A zu mergen. Das ist meistens nicht das, was du willst. Achte also immer darauf, wo du dich gerade befindest. Ein kurzer Check mit git branch schadet nie, bevor du tiefgreifende Änderungen vornimmst.
Die Gefahr von automatischen Merges
Ich bin kein Fan von automatischen Abläufen, wenn es um Code-Integration geht. Wenn du die Standardeinstellungen nutzt, erzeugt Git bei jedem Konflikt einen neuen Commit. Das bläht die Historie auf. In professionellen Teams, etwa bei großen Open-Source-Projekten oder in Firmen mit strengen Code-Reviews, ist eine saubere Historie Gold wert. Wir wollen eine lineare Erzählung unserer Entwicklung sehen, kein wirres Netz aus Linien, die sich ständig kreuzen.
Hier kommt Rebase ins Spiel. Anstatt die Änderungen zusammenzuführen, nimmt Rebase deine lokalen Commits, legt sie kurz beiseite, aktualisiert die Basis auf den neuesten Stand vom Server und setzt deine Commits dann oben wieder drauf. Das Ergebnis ist eine saubere, gerade Linie. Aber Vorsicht: Rebase verändert die Historie. Das darfst du niemals auf Zweigen machen, auf denen auch andere Leute arbeiten. Wenn du die Historie auf dem Server überschreibst, bringst du das gesamte Team in Schwierigkeiten.
Konfliktlösung ohne Panik
Wenn es knallt, dann richtig. Merge-Konflikte entstehen, wenn zwei Personen dieselbe Zeile in derselben Datei geändert haben. Git ist schlau, aber es kann nicht Gedanken lesen. Es weiß nicht, ob deine Änderung wichtiger ist als die deines Kollegen. In so einem Moment stoppt der Prozess. Die betroffenen Dateien werden markiert.
Viele Entwickler nutzen externe Tools zur Konfliktlösung. Das ist völlig legitim. Programme wie VS Code oder spezialisierte Merge-Tools zeigen dir beide Versionen nebeneinander an. Du entscheidest Zeile für Zeile, was bleiben darf. Wichtig ist hier: Nimm dir Zeit. Ein falsch gelöster Konflikt kann Bugs einführen, die erst Wochen später bemerkt werden. Nach der Lösung musst du die Dateien mit git add markieren und den Prozess mit einem Commit abschließen.
Strategien für saubere Workflows
In Deutschland legen wir Wert auf Ordnung und Struktur, und das sollte sich auch in deinem Repository widerspiegeln. Ein wildes Durcheinander von Commits ist wie eine unaufgeräumte Werkstatt. Man findet zwar alles irgendwann, aber es dauert doppelt so lange. Ein guter Workflow beginnt beim ersten Befehl des Tages. Bevor du anfängst zu programmieren, solltest du sicherstellen, dass dein Fundament aktuell ist.
Ein bewährtes Muster ist das "Pull-Rebase"-Prinzip. Viele Profis konfigurieren Git so, dass es standardmäßig Rebase verwendet. Das verhindert die unnötigen Merge-Commits. Du kannst das global für deinen Rechner einstellen. Das spart Tipparbeit und sorgt für ein ordentliches Log. Aber wie gesagt: Das gilt nur für deine privaten Feature-Branches. Auf dem Hauptzweig (Main oder Master) gelten andere Regeln.
Arbeiten in großen Teams
Wenn zwanzig Leute gleichzeitig an einem Projekt arbeiten, wird die Frequenz der Änderungen extrem hoch. Hier reicht ein einfaches Git Pull From A Remote Branch oft nicht aus, um den Überblick zu behalten. In solchen Umgebungen arbeiten wir oft mit Pull Requests oder Merge Requests. Das bedeutet, du schiebst deinen Code auf den Server, aber er wird nicht sofort in den Hauptzweig integriert. Stattdessen schauen sich Kollegen deine Änderungen an.
Dieser Prozess dient der Qualitätssicherung. Er gibt dir auch die Möglichkeit, deine lokale Kopie in Ruhe zu aktualisieren, während die Diskussion über deinen Code läuft. Wenn der Reviewer Änderungen verlangt, aktualisierst du deinen Zweig lokal und schiebst ihn wieder hoch. Erst wenn alle zufrieden sind, wird der Code final zusammengeführt. Das ist der Goldstandard in der modernen Softwareentwicklung.
Die Rolle von Git Hooks
Wusstest du, dass du Git automatisieren kannst? Mit sogenannten Hooks kannst du Skripte ausführen lassen, bevor oder nachdem bestimmte Aktionen passieren. Ein "Pre-Push"-Hook könnte beispielsweise sicherstellen, dass alle Tests grün sind, bevor du deinen Code auf den Server schlägst. Das verhindert, dass kaputter Code überhaupt erst die Runde macht. Es gibt auch "Post-Merge"-Hooks, die zum Beispiel deine Abhängigkeiten automatisch aktualisieren, wenn sich die entsprechende Konfigurationsdatei geändert hat. Das spart Zeit und reduziert menschliche Fehler.
Häufige Fehlerquellen und wie man sie umgeht
Einer der größten Fehler ist das Arbeiten auf einem veralteten Stand über einen langen Zeitraum. Ich habe Entwickler gesehen, die zwei Wochen lang in ihrem eigenen Saft geschmort haben, ohne einmal die Änderungen vom Hauptserver zu holen. Am Ende war der Merge so gewaltig und komplex, dass es drei Tage dauerte, die Konflikte zu lösen. Die goldene Regel lautet: Integriere oft. Mindestens einmal am Tag solltest du schauen, was die anderen gemacht haben.
Ein weiteres Problem ist das versehentliche Pushen von sensiblen Daten. Git vergisst nichts. Wenn du einmal ein Passwort oder einen API-Key in die Historie geschrieben hast, ist es dort gespeichert, selbst wenn du es im nächsten Commit löschst. In so einem Fall hilft nur noch das radikale Umschreiben der Historie mit Werkzeugen wie dem BFG Repo-Cleaner oder git filter-branch. Aber das ist ein chirurgischer Eingriff am offenen Herzen des Projekts. Vermeide es lieber von vornherein. Nutze .gitignore Dateien konsequent.
Die Bedeutung der .gitignore Datei
Die .gitignore Datei ist dein bester Freund. Sie sagt Git, welche Dateien es ignorieren soll. Das betrifft oft kompilierte Binärdateien, Logfiles oder lokale Konfigurationen deiner Entwicklungsumgebung. Wenn diese Dateien im Repository landen, verursachen sie ständig unnötige Konflikte beim Abrufen von Daten. Ein sauberes Repository enthält nur den Quellcode und die notwendigen Konfigurationen, um das Projekt zu bauen.
Auf Portalen wie GitHub findest du Vorlagen für fast jede Programmiersprache und jedes Betriebssystem. Es gibt keinen Grund, das Rad neu zu erfinden. Lade dir eine passende Vorlage herunter und passe sie an deine Bedürfnisse an. Das hält dein Repository schlank und übersichtlich.
Umgang mit großen Dateien
Git ist nicht für riesige Binärdateien wie hochauflösende Videos oder komplexe 3D-Modelle ausgelegt. Wenn du solche Daten verwalten musst, solltest du dir Git LFS (Large File Storage) ansehen. LFS speichert nur Referenzen im eigentlichen Repository, während die schweren Daten auf einem separaten Server liegen. Das beschleunigt den Klonvorgang und das Abrufen von Updates enorm. Ohne LFS würde jedes Mal die gesamte Historie dieser riesigen Dateien heruntergeladen werden, was die Arbeit unerträglich langsam macht.
Fortgeschrittene Techniken für Profis
Wenn du die Grundlagen beherrschst, kannst du tiefer graben. Kennst du git cherry-pick? Damit kannst du einen einzelnen, spezifischen Commit von einem anderen Zweig in deinen aktuellen Zweig kopieren. Das ist extrem nützlich, wenn ein Kollege einen Bugfix auf einem Feature-Zweig gemacht hat, den du sofort in deinem eigenen Zweig brauchst, ohne den Rest seiner (vielleicht noch unfertigen) Arbeit zu übernehmen.
Ein weiteres mächtiges Werkzeug ist git stash. Wenn du gerade mitten in einer Änderung steckst, aber dringend den Stand vom Server ziehen musst, willst du deine unfertige Arbeit nicht committen. Mit Stash "verstaust" du deine Änderungen auf einem temporären Stapel. Dein Arbeitsverzeichnis ist wieder sauber. Jetzt kannst du die Daten vom Server holen, eventuelle Konflikte klären und danach deine Arbeit mit git stash pop wieder hervorholen. Das ist im Alltag ein Lebensretter.
Reflogs nutzen wenn alles schiefgeht
Hast du jemals einen Commit gelöscht oder dich so verheddert, dass du dachtest, alles sei verloren? Keine Panik. Git protokolliert fast jede Bewegung deines Branch-Pointers im sogenannten Reflog. Mit git reflog kannst du sehen, wo dein Zweig in den letzten Stunden und Tagen stand. Du kannst zu jedem dieser Zustände zurückkehren, selbst wenn die Commits nicht mehr in der normalen Historie sichtbar sind. Das ist das Sicherheitsnetz, das dich vor dem totalen Datenverlust bewahrt.
Submodule und ihre Tücken
In komplexen Projekten nutzt man oft andere Repositories als Unterprojekte. Git Submodule erlauben es dir, ein fremdes Repository in einem Unterordner deines eigenen Projekts einzubinden. Das klingt praktisch, ist aber in der Handhabung oft sperrig. Wenn du Daten abrufst, werden die Submodule nicht automatisch aktualisiert. Du musst explizite Befehle nutzen, um auch dort den neuesten Stand zu sichern. Viele Entwickler bevorzugen heute Paketmanager wie npm oder Maven, aber in der C++ Welt oder bei Systemprogrammierung sind Submodule nach wie vor weit verbreitet. Eine Dokumentation dazu findest du bei der Git Community.
Praktische Schritte zur Fehlervermeidung
Damit du in Zukunft weniger Stress hast, gewöhne dir eine feste Routine an. Softwareentwicklung ist Handwerk, und Handwerk braucht Disziplin. Hier sind die Schritte, die ich jedem empfehle, bevor er tiefer in die Materie einsteigt.
- Status prüfen: Bevor du irgendetwas tust, tippe
git status. Du musst wissen, ob dein Arbeitsverzeichnis sauber ist. Uncommittete Änderungen führen oft zu Problemen beim Abrufen von Daten. - Fetch vor Pull: Gewöhne dir an, erst
git fetchzu nutzen. Schau dir mitgit log origin/dein-zweigan, was die Kollegen eigentlich gemacht haben, bevor du es blind in deinen Code mischst. Wissen ist Macht. - Sprechende Commit-Messages: Schreib keine Nachrichten wie "Update" oder "Fix". Beschreibe kurz, WAS du gemacht hast und WARUM. Das hilft nicht nur deinen Kollegen, sondern auch dir selbst, wenn du in drei Monaten versuchst zu verstehen, warum ein bestimmter Konflikt aufgetreten ist.
- Zweige kurzlebig halten: Versuche, Feature-Branches so schnell wie möglich wieder in den Hauptzweig zu integrieren. Je länger ein Zweig isoliert existiert, desto schmerzhafter wird die spätere Zusammenführung.
- Regelmäßige Backups: Auch wenn Git ein verteiltes System ist, schadet es nicht, wichtige Stände auf einem externen Server oder einer Cloud zu sichern. Ein Hardwaredefekt am Laptop kann sonst einen ganzen Tag Arbeit vernichten, wenn du noch nicht gepusht hast.
Es gibt keine magische Abkürzung zum Git-Experten. Es ist wie beim Erlernen eines Instruments: Du musst üben, Fehler machen und daraus lernen. Die offizielle Dokumentation ist zwar sehr technisch, aber extrem präzise. Wer wirklich verstehen will, wie die Daten fließen, sollte die Git-Dokumentation regelmäßig konsultieren. Dort werden auch komplexe Szenarien wie Octo-Merges oder komplizierte Rebase-Strategien erklärt.
Letztlich ist Git ein Werkzeug, das dich unterstützen soll, nicht behindern. Wenn du merkst, dass du mehr Zeit mit der Verwaltung deiner Versionen verbringst als mit dem eigentlichen Programmieren, läuft etwas falsch. Meistens ist es ein Zeichen dafür, dass der Workflow im Team zu kompliziert ist oder dass grundlegende Konzepte nicht verstanden wurden. Redet im Team darüber. Ein gemeinsames Verständnis darüber, wie man Code integriert, ist wichtiger als jeder automatisierte Prozess.
In der Welt der Softwareentwicklung ist Stillstand Rückschritt. Die Werkzeuge entwickeln sich weiter, und auch Git bekommt regelmäßig neue Funktionen, die das Leben leichter machen. Bleib neugierig und probiere neue Workflows in einem Test-Repository aus, bevor du sie auf das Hauptprojekt loslässt. So minimierst du das Risiko und steigerst deine Produktivität nachhaltig. Am Ende des Tages geht es darum, stabilen und wartbaren Code zu produzieren. Git ist dabei lediglich dein treuer Begleiter auf diesem Weg.
Gehe jetzt an dein aktuelles Projekt und prüfe, ob deine Upstream-Verbindungen korrekt gesetzt sind. Nutze die Gelegenheit, um verwaiste lokale Zweige zu löschen, die auf dem Server bereits gelöscht wurden. Ein sauberer Arbeitsplatz ist der erste Schritt zu fehlerfreiem Code. Du wirst merken, dass die Arbeit viel flüssiger von der Hand geht, wenn du dich nicht ständig über unvorhergesehene Fehlermeldungen ärgern musst. Viel Erfolg beim nächsten Commit!



