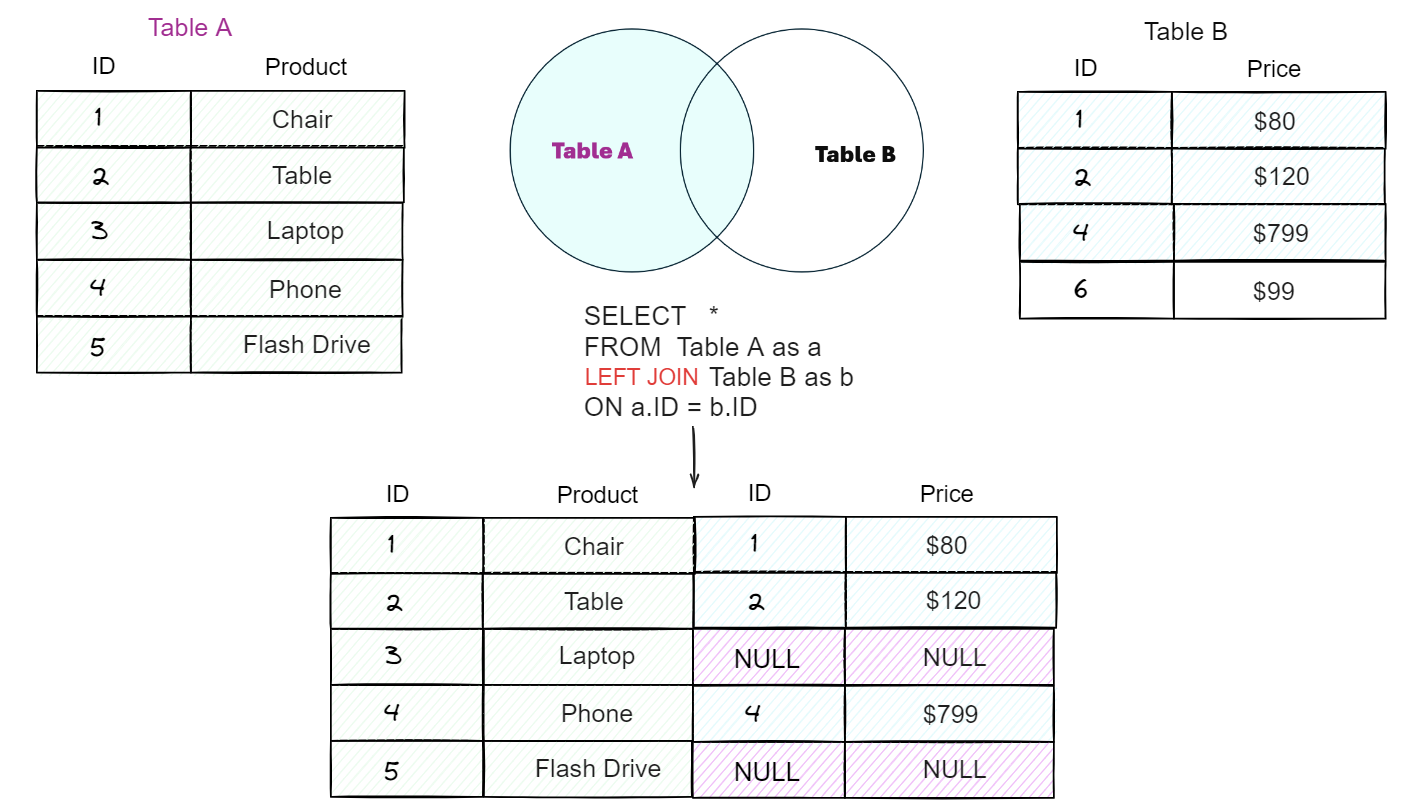
In der Architektur moderner Informationssysteme spielt die Auswahl der richtigen Verknüpfungslogik eine wesentliche Rolle für die Systemleistung und Datenintegrität. Softwareentwickler und Datenbankadministratoren bewerten aktuell vermehrt die Performance-Unterschiede bei Abfragen großer Datensätze, wobei die Debatte Inner Join Vs Left Join im Mittelpunkt technischer Optimierungsstrategien steht. Laut einer Analyse der Cloud Native Computing Foundation hängen die Latenzzeiten komplexer Anwendungen maßgeblich davon ab, wie effizient relationale Datenbanken Datensätze aus verschiedenen Tabellen zusammenführen.
Die technische Entscheidung zwischen diesen Methoden beeinflusst direkt die Sichtbarkeit von Informationen in Endbenutzeranwendungen. Während die eine Variante nur übereinstimmende Datensätze liefert, stellt die andere sicher, dass alle Informationen der primären Quelle erhalten bleiben, selbst wenn keine Entsprechungen in der Sekundärtabelle existieren. Dr. Karsten Schmidt, Dozent für Wirtschaftsinformatik an der Technischen Universität München, betonte in einem Fachvortrag, dass die Wahl der Join-Strategie nicht nur eine Frage der Logik, sondern der Speicherressourcen sei.
Die Relevanz dieser Unterscheidung zeigt sich besonders bei der Skalierung von Unternehmensanwendungen. Da Firmen immer größere Datenmengen verarbeiten, führen ineffiziente Abfragen zu unnötigen CPU-Zyklen und erhöhen die Betriebskosten in Cloud-Umgebungen wie AWS oder Microsoft Azure. Die korrekte Implementierung der Logik entscheidet darüber, ob ein System unter Last stabil bleibt oder Verzögerungen bei der Antwortzeit aufweist.
Technische Spezifikationen Und Die Debatte Inner Join Vs Left Join
Bei der Betrachtung der internen Verarbeitungsmechanismen von SQL-Datenbanken wie PostgreSQL oder MySQL zeigen sich fundamentale Unterschiede in der Ausführungsplanung. Die erstgenannte Methode filtert das Ergebnis dahingehend, dass nur Zeilen ausgegeben werden, bei denen der Verknüpfungsschlüssel in beiden beteiligten Relationen vorhanden ist. Im Gegensatz dazu behält die alternative Variante alle Zeilen der linken Tabelle bei und füllt die Spalten der rechten Tabelle bei fehlenden Übereinstimmungen mit Nullwerten auf.
Algorithmen Zur Abfrageoptimierung
Moderne Datenbank-Engines nutzen Kostenmodelle, um den schnellsten Weg für den Datenabruf zu berechnen. Laut der offiziellen Dokumentation von PostgreSQL hängen diese Kosten von der Tabellengröße und der Existenz von Indizes ab. Ein Optimizer kann bei einer strikten Schnittmenge oft effizientere Hash-Joins verwenden, während die Erhaltung aller Datensätze einer Seite zusätzliche Prüfungsschritte erfordert.
Diese internen Prozesse sind für die Anwendungsgeschwindigkeit kritisch, da jeder zusätzliche Rechenschritt bei Millionen von Datensätzen spürbare Zeitverluste verursacht. Entwickler müssen daher genau abwägen, welche Ergebnismenge für den spezifischen Geschäftsprozess erforderlich ist. Eine falsche Wahl führt entweder zu Datenverlust in der Anzeige oder zu einer Überlastung des Arbeitsspeichers durch unnötige Nullwerte.
Auswirkungen Auf Die Datenqualität In Unternehmen
Die Wahl der Verknüpfungsmethode hat weitreichende Konsequenzen für die Berichterstattung und Analyse in Konzernen. Wenn Analysten beispielsweise Verkaufsdaten mit Kundeninformationen verknüpfen, bestimmt die Logik darüber, ob auch Kunden ohne bisherige Käufe im Bericht erscheinen. Die International Business Machines Corporation (IBM) weist in ihren Schulungsunterlagen für Datenwissenschaftler darauf hin, dass unvollständige Ergebnismengen zu Fehlinterpretationen der Marktrealität führen können.
Fehler in der Abfragestruktur können dazu führen, dass wichtige Kennzahlen wie der durchschnittliche Umsatz pro Nutzer falsch berechnet werden. Falls Datensätze aufgrund fehlender Verknüpfungspartner im Ergebnis fehlen, unterschätzt das System unter Umständen die Gesamtzahl der aktiven Konten. Dies führt zu einer Verzerrung der statistischen Basis, die für strategische Vorstandsentscheidungen herangezogen wird.
Strategien Zur Fehlervermeidung
Um solche Diskrepanzen zu minimieren, setzen viele Organisationen auf automatisierte Testing-Tools für SQL-Code. Diese Werkzeuge vergleichen die Ergebnisse verschiedener Join-Typen, um sicherzustellen, dass keine unbeabsichtigten Datenverluste auftreten. Experten der Gesellschaft für Informatik empfehlen zudem eine strikte Dokumentation der Datenmodelle, um Klarheit über die Beziehungen zwischen den Tabellen zu schaffen.
Die Verwendung von Schemavalidierungen hilft dabei, die Integrität der Fremdschlüssel zu wahren. Wenn die Datenbankstruktur konsistent gepflegt wird, reduziert sich das Risiko, dass eine falsche Verknüpfungslogik zu leeren Feldern in kritischen Anwendungen führt. Dennoch bleibt die manuelle Überprüfung durch erfahrene Datenbankentwickler ein wesentlicher Bestandteil der Qualitätssicherung.
Kritische Betrachtung Und Häufige Implementierungsfehler
Trotz der klaren theoretischen Definitionen kommt es in der Praxis häufig zu Fehlern bei der Anwendung von Inner Join Vs Left Join in komplexen Umgebungen. Ein häufiges Problem ist die sogenannte Datenaufblähung, wenn eine Eins-zu-viele-Beziehung besteht und die Abfrage nicht korrekt gruppiert wird. Dies führt dazu, dass Datensätze mehrfach im Ergebnis erscheinen, was die Performance drastisch verschlechtert.
Kritiker bemängeln oft, dass junge Softwareentwickler aus Bequemlichkeit zu häufig die Variante wählen, die alle Daten beibehält, ohne die Auswirkungen auf den Index-Scan zu prüfen. Microsoft stellt in seiner Dokumentation zu SQL Server fest, dass unnötige äußere Verknüpfungen den Abfrageoptimierer daran hindern können, bestimmte Suchpfade zu nutzen. Dies führt zu einem langsameren Systemverhalten, das oft erst bei hohen Nutzerzahlen bemerkt wird.
Ein weiteres Problem ist die fehlerhafte Filterung in der Suchbedingung. Wenn Filterkriterien für die rechte Tabelle in der WHERE-Klausel statt in der JOIN-Bedingung platziert werden, verwandelt sich eine eigentlich beabsichtigte umfassende Verknüpfung logisch oft ungewollt in eine strikte Schnittmenge. Diese subtilen logischen Fehler sind schwer zu finden und verursachen regelmäßig Ausfälle in automatisierten Reporting-Systemen.
Infrastrukturkosten Und Ressourcenverbrauch In Der Cloud
Die ökonomische Komponente der Datenbankabfragen gewinnt durch die Umstellung auf verbrauchsbasierte Cloud-Preismodelle an Bedeutung. Unternehmen zahlen für die Rechenzeit und den Speicher-I/O, die ihre Abfragen verursachen. Laut einem Bericht der Gartner Group entfällt ein erheblicher Teil der Cloud-Verschwendung auf ineffizienten Code und schlecht optimierte Datenbankzugriffe.
Wenn eine Abfrage aufgrund einer suboptimalen Verknüpfungslogik statt Millisekunden mehrere Sekunden benötigt, steigen die Kosten für die Instanzen linear an. In großen Clustern mit Tausenden von gleichzeitigen Anfragen summieren sich diese Ineffizienzen zu erheblichen monatlichen Mehrkosten. CIOs fordern daher zunehmend eine stärkere Sensibilisierung der Entwicklungsteams für die zugrunde liegende Hardware-Last.
Die Optimierung von Abfragen wird damit zu einem direkten Faktor für die Rentabilität digitaler Geschäftsmodelle. Techniken wie das Query-Profiling erlauben es Teams, genau zu sehen, welche Operationen die meisten Ressourcen verbrauchen. Oft zeigt sich dabei, dass eine Umstellung der Verknüpfungsart in Kombination mit einer besseren Indizierung die Last um über 50% senken kann.
Die Rolle Von Künstlicher Intelligenz Bei Der SQL-Optimierung
Ein neuer Trend in der Branche ist der Einsatz von maschinellem Lernen zur automatischen Verbesserung von Datenbankabfragen. Unternehmen wie Oracle integrieren Funktionen in ihre Systeme, die das Nutzerverhalten analysieren und Vorschläge für die effizienteste Verknüpfungsmethode machen. Diese Systeme können erkennen, ob eine Abfrage regelmäßig zu viele unnötige Daten lädt und die Logik im Hintergrund anpassen.
Diese Entwicklung wird von Experten zwiespältig betrachtet. Während die Automatisierung die Arbeit der Administratoren erleichtert, besteht die Gefahr, dass das tiefe Verständnis für die zugrunde liegenden mathematischen Mengenoperationen verloren geht. Stefan Meyer, Softwarearchitekt bei einem führenden deutschen Finanzdienstleister, warnte davor, sich blind auf die Vorschläge der KI zu verlassen, da diese die geschäftliche Bedeutung der Daten nicht versteht.
Trotz dieser Bedenken zeigen Daten von Branchenanalysten, dass die Akzeptanz solcher autonomen Datenbankfunktionen jährlich um etwa 15% steigt. Besonders im Bereich Big Data, wo manuelle Optimierungen kaum noch zu bewältigen sind, bieten diese Tools einen notwendigen Geschwindigkeitsvorteil. Die KI übernimmt dabei die Aufgabe, aus Millionen möglicher Ausführungspläne den mathematisch idealen Weg zu finden.
Zukunftsorientierte Ansätze In Der Datenverarbeitung
In den kommenden Jahren wird die Bedeutung präziser Abfragelogik durch die Einführung von Echtzeit-Analysesystemen weiter zunehmen. Es bleibt abzuwarten, wie sich neue Datenbanktechnologien, die nicht mehr auf klassischen relationalen Modellen basieren, auf die etablierten Verknüpfungsstandards auswirken werden. Forscher am Massachusetts Institute of Technology arbeiten bereits an Systemen, die Datenbeziehungen dynamisch während der Laufzeit ohne feste Joins berechnen können.
Ungeklärt bleibt bisher, inwieweit diese Innovationen die klassischen SQL-Strukturen vollständig ersetzen können oder ob sie lediglich eine Ergänzung für spezielle Anwendungsfälle darstellen. Beobachter der Branche erwarten, dass die Ausbildung von Dateningenieuren künftig einen noch stärkeren Fokus auf die mathematischen Grundlagen der Mengenlehre legen wird. Die präzise Steuerung des Datenflusses bleibt die Grundvoraussetzung für die nächste Generation leistungsfähiger Anwendungen.



