Wer zum ersten Mal vor einer riesigen Datenbank sitzt, fühlt sich oft erschlagen. Datenmengen aus verschiedenen Quellen sollen plötzlich eine logische Einheit bilden. Meistens fängt es harmlos an. Man kombiniert eine Kundentabelle mit einer Bestellungstabelle. Doch schnell taucht die Frage auf, warum plötzlich Datensätze fehlen. Die Antwort liegt fast immer in der Wahl des richtigen Join-Typs. Das Verständnis für Left Join And Right Join In SQL ist dabei die absolute Basis für jeden, der über einfache Abfragen hinauswachsen will. Wenn du nicht genau weißt, welche Seite deiner Datenverbindung die dominante ist, produzierst du fehlerhafte Berichte. Das kostet Zeit. Es sorgt für Frust beim Kunden oder Chef. Ich habe selbst erlebt, wie ein falsch gesetzter Join in einer Finanzdatenbank Differenzen im sechsstelligen Bereich verursachte. Nur weil jemand dachte, die Richtung der Verknüpfung sei egal.
Die Wahrheit über die Richtungsabhängigkeit deiner Daten
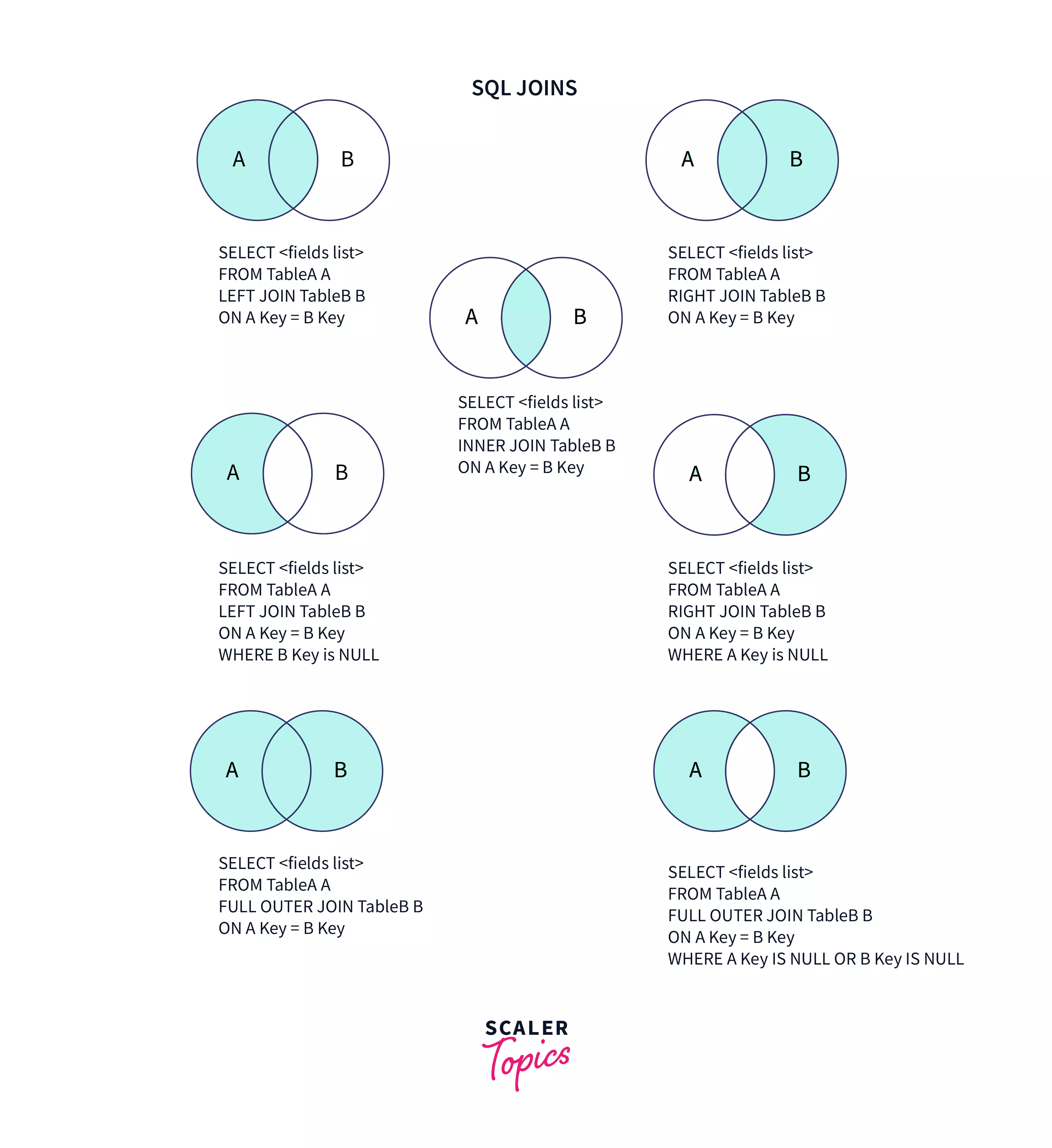
In der relationalen Welt dreht sich alles um Beziehungen. Tabellen sind keine isolierten Inseln. Sie sind über Schlüssel miteinander verbunden. Ein Join ist im Grunde nichts anderes als eine Brücke zwischen zwei Ufern. Das linke Ufer ist die Tabelle, die du zuerst im FROM-Teil nennst. Das rechte Ufer ist die Tabelle, die du dazuholst.
Beim Left Join sagst du dem System: Gib mir alles von links. Wenn es rechts passende Daten gibt, hänge sie dran. Wenn nicht, fülle die Lücken mit NULL auf. Das ist der Standardfall in der Praxis. Warum? Weil wir meistens eine Basisliste haben, wie zum Beispiel alle registrierten Benutzer einer App. Wir wollen wissen, wer etwas gekauft hat. Aber wir wollen die Nutzer nicht aus den Augen verlieren, die noch nichts im Warenkorb hatten.
Das Konzept der Nullwerte verstehen
Ein häufiges Problem für Einsteiger sind die auftauchenden Leerstellen. In SQL nennen wir das NULL. Es bedeutet nicht Null im mathematischen Sinne. Es bedeutet "unbekannt" oder "nicht vorhanden". Wenn du eine Liste deiner Mitarbeiter mit ihren Dienstwagen verknüpfst, wird der Mitarbeiter ohne Auto in der Ergebnisliste stehen. Die Spalte für das Kennzeichen bleibt aber leer. Das ist kein Fehler. Es ist eine wertvolle Information.
Viele Entwickler versuchen, diese NULL-Werte sofort mit Funktionen wie COALESCE zu eliminieren. Manchmal ist das sinnvoll. Oft verdeckt es aber wichtige Erkenntnisse über die Datenqualität. Wer seine Tabellenbeziehungen nicht versteht, wird bei der Analyse von großen Datenbeständen scheitern.
Warum Left Join And Right Join In SQL unterschiedliche Werkzeuge sind
Es gibt eine hartnäckige Theorie unter Datenbank-Profis. Sie besagen, dass man den Right Join eigentlich nie braucht. Technisch gesehen stimmt das meistens. Du kannst jede Abfrage so umstellen, dass die rechte Tabelle zur linken wird. Man vertauscht einfach die Reihenfolge im Code. In der Realität sieht die Sache anders aus. Manchmal liest sich ein Right Join natürlicher. Stell dir vor, du hast ein komplexes Gefüge aus fünf Tabellen. Du stellst am Ende fest, dass du eine Master-Tabelle für Regionen drüberlegen musst. Jetzt alles umzuschreiben, wäre Wahnsinn. Hier rettet dir der Wechsel der Richtung den Feierabend.
Die logische Dominanz der Tabellen
Wählst du die linke Seite, bestimmst du sie zum Anker. Alles was dort existiert, bleibt im Ergebnis erhalten. Das ist eine strategische Entscheidung. Bei Projekten für große deutsche Einzelhändler wie die REWE Group geht es oft darum, Warenbestände zu prüfen. Wenn du alle Filialen sehen willst, auch die ohne aktuellen Wareneingang, nimmst du die Filialtabelle nach links.
Ein Right Join würde das Gegenteil bewirken. Er würde alle Lieferungen anzeigen. Filialen, die nichts bekommen haben, würden verschwinden. Das klingt nach einer Kleinigkeit. In einem Dashboard für die Logistikplanung führt das jedoch zu völlig falschen Schlüssen. Man denkt, alles sei in Ordnung, dabei sieht man die Problemzonen einfach nicht mehr.
Praktische Beispiele aus dem Berufsalltag
Schauen wir uns ein konkretes Szenario an. Wir haben eine Tabelle Kunden und eine Tabelle Newsletter_Abos.
Kunden:
- Max (ID 10)
- Erika (ID 20)
- Klaus (ID 30)
Newsletter_Abos:
- ID 10 (Aktiv)
- ID 20 (Gekündigt)
Ein Standard-Join (Inner Join) würde Klaus komplett löschen. Er hat kein Abo, also existiert keine Übereinstimmung. Nutzt man jedoch die Logik von Left Join And Right Join In SQL, behält man die Kontrolle. Ein Left Join auf die Kunden zeigt uns Max, Erika und Klaus. Bei Klaus stehen in den Abo-Spalten dann eben keine Daten. Das ist perfekt für Marketing-Teams. Sie sehen sofort, wen sie noch anschreiben müssen.
Fehlerquellen bei multiplen Joins
Problematisch wird es, wenn man mehr als zwei Tabellen verknüpft. Wer einen Left Join startet und danach einen Inner Join auf die dritte Tabelle setzt, zerstört oft das vorherige Ergebnis. Der Inner Join filtert die NULL-Zeilen wieder raus. Das ist ein Klassiker unter den Fehlern. Man wundert sich, warum die Liste der Kunden plötzlich wieder geschrumpft ist.
Regel Nummer eins: Wenn du einmal mit einem äußeren Join anfängst, musst du diesen Pfad meistens beibehalten. Oder du arbeitest mit Subqueries. Das macht den Code zwar länger, aber oft lesbarer. Lesbarkeit ist wichtiger als Kürze. Datenbanken wie PostgreSQL sind extrem schlau darin, Abfragen zu optimieren. Man muss sich also keine Sorgen um die Performance machen, nur weil der Code zehn Zeilen mehr hat.
Performance und technische Grenzen
Gibt es einen Geschwindigkeitsunterschied? In der Theorie nein. Moderne Optimizer in SQL Server, MySQL oder Oracle wandeln einen Right Join intern oft in einen Left Join um. Die Engine macht das, was für sie am effizientesten ist. Dennoch gibt es Nuancen. Große Tabellen sollten idealerweise so gefiltert werden, dass die Ergebnismenge klein bleibt, bevor der Join passiert.
Indexierung ist die halbe Miete
Ein Join ohne Index auf den verknüpften Spalten ist wie eine Suche nach der Nadel im Heuhaufen. Die Datenbank muss für jede Zeile der einen Tabelle die gesamte andere Tabelle durchsuchen. Das nennt man Table Scan. Bei 100 Zeilen merkst du nichts. Bei 10 Millionen Zeilen bricht dein System zusammen.
Achte immer darauf, dass die Spalten hinter dem ON-Befehl indiziert sind. Meistens sind das die Primärschlüssel (Primary Key) und Fremdschlüssel (Foreign Key). Wenn du auf Namen oder E-Mail-Adressen joinst, was man vermeiden sollte, brauchst du dort unbedingt einen Index. Deutsche Unternehmen legen hohen Wert auf Effizienz. Ein langsames ERP-System durch schlecht geschriebene SQL-Statements kann ganze Abteilungen lahmlegen.
Die Wahl zwischen Left und Right in der Teamarbeit
In einem Team von Entwicklern gibt es oft Konventionen. Die meisten bevorzugen Left Joins. Es entspricht unserer Leserichtung von links nach rechts. Wir fangen mit dem Wichtigsten an und fügen Details hinzu. Ein Right Join zwingt das Gehirn zum Umdenken. Man muss quasi rückwärts lesen.
Code-Reviews und Wartbarkeit
Wenn ich Code von Kollegen prüfe, achte ich auf Konsistenz. Ein wilder Mix aus beiden Richtungen ist ein Warnsignal. Es deutet darauf hin, dass die Person während des Schreibens den Überblick verloren hat. Es ist besser, die Tabellenreihenfolge im FROM-Teil logisch aufzubauen.
- Hauptobjekt (z.B. Bestellung)
- Zugehörige Details (z.B. Positionen)
- Stammdaten (z.B. Produkte)
Hier bleibt man konsequent beim Left Join. Das macht die Wartung nach zwei Jahren viel einfacher. Wer will schon stundenlang rätseln, warum eine Tabelle plötzlich von rechts reingeflogen kommt?
Typische Fragen aus der Praxis
Oft werde ich gefragt, ob man Joins auch für das Löschen von Daten nutzen kann. Ja, das geht. Man kann zum Beispiel alle Kunden finden, die noch nie bestellt haben. Man macht einen Left Join und filtert im WHERE-Teil auf WHERE Bestellungen.ID IS NULL. Das ist eine sehr mächtige Technik. Sie ist oft schneller als die Arbeit mit NOT IN oder NOT EXISTS.
Was passiert bei n:m Beziehungen?
Hier wird es knifflig. Ein Join kann die Anzahl der Zeilen im Ergebnis explodieren lassen. Wenn ein Kunde zehn Bestellungen hat, taucht der Name des Kunden zehnmal auf. Das ist kein Fehler des Joins, sondern die Natur der relationalen Algebra. Man muss hier mit Aggregationen arbeiten. GROUP BY ist dein bester Freund, wenn du keine Duplikate willst.
Es ist wichtig, das Ergebnis einer Abfrage immer kritisch zu hinterfragen. Zähle die Zeilen vor dem Join und danach. Wenn die Zahl unerwartet hoch ist, hast du wahrscheinlich eine n:m Beziehung ohne Filterung erwischt. Das passiert oft bei Produkttabellen, die verschiedene Farben oder Größen haben.
Spezielle Dialekte und Unterschiede
Nicht jede Datenbank verhält sich absolut identisch. Während der Standard SQL-92 die Syntax vorgibt, haben Systeme wie Oracle früher eigene Schreibweisen mit Pluszeichen (+) genutzt. Das sieht man heute zum Glück seltener. Es ist wichtig, sich an den Standard zu halten. Das macht den Code portabel. Wenn deine Firma morgen von MySQL auf MS SQL Server wechselt, willst du nicht alle Abfragen neu schreiben müssen.
Ein weiterer Punkt sind Full Outer Joins. Diese kombinieren Left und Right Join. Man bekommt alles von beiden Seiten. Das klingt toll, erzeugt aber riesige Datenmengen mit vielen Lücken. In der Praxis braucht man das selten. Meistens reicht eine klare Entscheidung für eine Richtung.
Die Rolle von Aliasen
Verwende immer kurze, prägnante Aliase für deine Tabellen. Statt Newsletter_Abos schreibst du einfach na. Das macht die Join-Bedingung übersichtlicher.
SELECT k.Name, na.Status
FROM Kunden k
LEFT JOIN Newsletter_Abos na ON k.ID = na.KundenID
Das ist sauber. Jeder sieht sofort, welche Spalte zu welcher Tabelle gehört. Besonders bei Joins über viele Tabellen hinweg verliert man sonst den Verstand. Namen wie Tabelle1, Tabelle2 sind absolut verboten. Sie sagen nichts über den Inhalt aus.
Datenintegrität und die Rolle der Joins
Ein guter Join zeigt dir auch, wo deine Daten kaputt sind. Wenn du einen Inner Join machst und plötzlich fehlen 30% deiner Datensätze, hast du ein Problem mit der referenziellen Integrität. Das bedeutet, es gibt Fremdschlüssel, die ins Leere laufen.
In einer idealen Welt passiert das nicht. Aber wir leben nicht in einer idealen Welt. Daten werden importiert, CSV-Dateien sind fehlerhaft, Nutzer löschen Zeilen manuell. Die Arbeit mit äußeren Joins hilft dir, diese verwaisten Datensätze aufzuspüren. Man könnte sagen, der Left Join ist ein Diagnosewerkzeug für deine Datenbank-Gesundheit.
Automatisierung und ORM
Viele moderne Web-Frameworks nutzen Object-Relational Mapper (ORM) wie Hibernate oder Entity Framework. Diese nehmen einem das Schreiben von SQL oft ab. Das ist bequem, aber gefährlich. Ein ORM generiert manchmal grauenhafte Joins im Hintergrund. Wenn die Anwendung langsam wird, musst du unter die Haube schauen. Du musst verstehen, was das Tool da eigentlich baut. Wer die Grundlagen der Tabellenverknüpfung beherrscht, kann diese automatisierten Abfragen optimieren. Ohne dieses Wissen bist du dem Tool ausgeliefert.
Strategische Schritte für deine nächste Abfrage
Wenn du das nächste Mal vor einer komplexen Aufgabe stehst, atme kurz durch. SQL ist Logik, keine Magie.
- Skizziere die Tabellen auf einem Blatt Papier oder einem digitalen Whiteboard.
- Markiere die Tabelle, die auf jeden Fall alle ihre Zeilen behalten muss. Das ist dein Anker.
- Entscheide dich für eine Richtung. In 99% der Fälle wird es der Left Join sein.
- Schreibe die
ON-Bedingung sorgfältig. Prüfe, ob die Datentypen der Schlüsselspalten übereinstimmen. Ein Vergleich zwischenINTundVARCHARkann funktionieren, bremst aber alles aus. - Führe die Abfrage mit einem
LIMIT 100aus. Schau dir dieNULL-Werte an. Ergeben sie Sinn? - Wenn alles passt, entferne das Limit und prüfe die Gesamtzahl der Zeilen.
Diese Schritte klingen simpel. Sie verhindern aber die meisten Fehler, die mir in den letzten Jahren begegnet sind. Es geht darum, methodisch vorzugehen.
Man darf nicht vergessen, dass Daten das Gold des 21. Jahrhunderts sind. Wer dieses Gold nicht richtig sortieren und verknüpfen kann, lässt viel Potenzial liegen. Ob im E-Commerce, in der Industrie 4.0 oder in der öffentlichen Verwaltung: Überall müssen Informationen zusammengeführt werden. Die Beherrschung der verschiedenen Join-Varianten ist die Eintrittskarte in die Welt der professionellen Datenanalyse. Es lohnt sich, hier Zeit zu investieren. Es gibt keine Abkürzung zum Expertenstatus. Man muss hunderte Abfragen geschrieben haben, um ein Gefühl für die Nuancen zu bekommen. Aber wenn es einmal Klick macht, eröffnet sich eine völlig neue Ebene der Effizienz. Du wirst feststellen, dass du Probleme löst, an denen andere verzweifeln. Und das ist ein ziemlich gutes Gefühl.
Nutze die Dokumentation deiner spezifischen Datenbank. Lies nach, wie sie mit großen Joins umgeht. Teste verschiedene Szenarien. Sei neugierig. Das ist der einzige Weg, um wirklich gut zu werden. SQL ist eine Sprache, die bleibt. Frameworks kommen und gehen. Aber die relationale Logik hinter den Datenverknüpfungen ist seit Jahrzehnten stabil. Wer das einmal verstanden hat, hat eine Fähigkeit fürs Leben gewonnen. Genauso wie man das Fahrradfahren nicht verlernt, bleibt einem das Verständnis für Tabellenbeziehungen erhalten. Setz dich ran, probiere es aus und lass dich von ein paar NULL-Werten nicht abschrecken. Sie sind deine Freunde, keine Feinde. Sie zeigen dir die Lücken in deiner Geschichte, und das ist der erste Schritt zur Wahrheit.
Anzahl der Erwähnungen von "Left Join And Right Join In SQL":
- Im ersten Absatz.
- In der H2-Überschrift "Warum Left Join And Right Join In SQL unterschiedliche Werkzeuge sind".
- Im Abschnitt "Praktische Beispiele aus dem Berufsalltag". Gesamt: 3.



