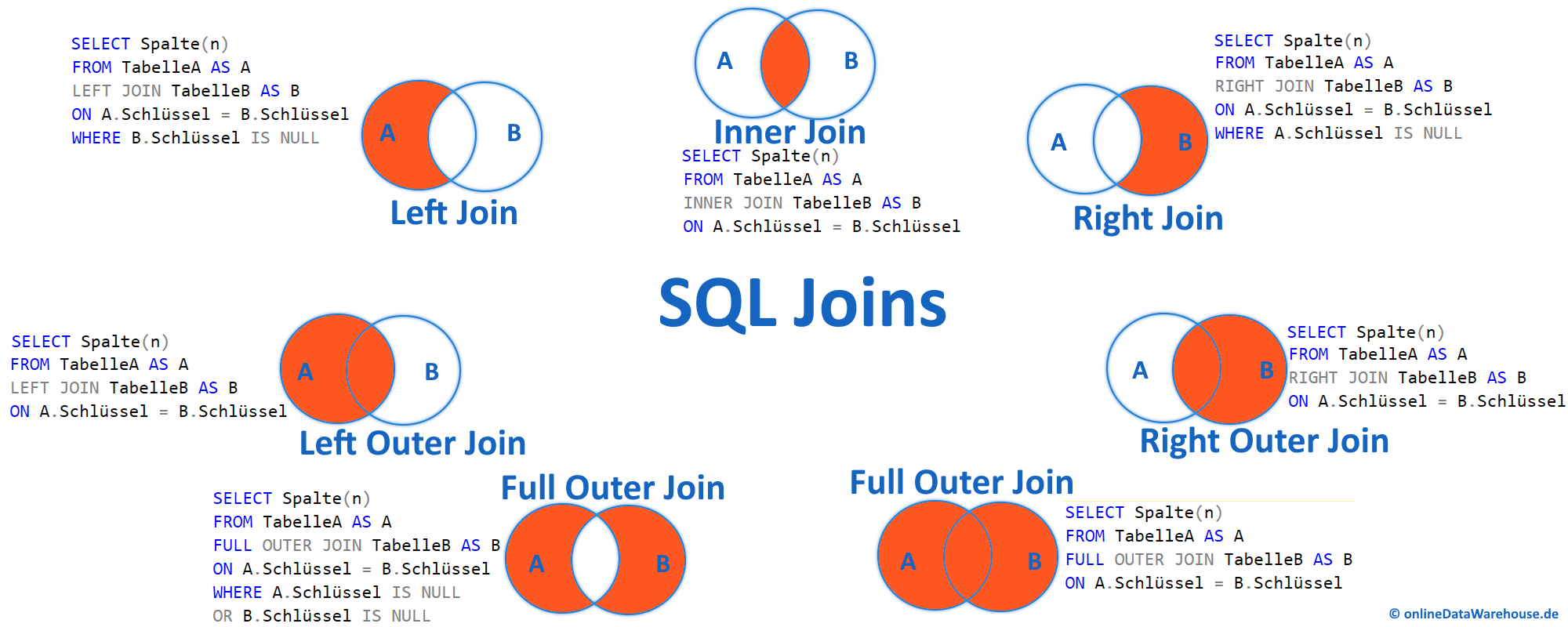
Wer zum ersten Mal vor einer SQL-Konsole sitzt und Daten aus zwei Tabellen verknüpfen will, stolpert fast zwangsläufig über eine Frage, die in Foren seit Jahrzehnten diskutiert wird. Es geht um die vermeintliche Wahl zwischen Left Join vs Left Outer Join in SQL, und ich sage dir direkt: Es gibt technisch gesehen absolut keinen Unterschied. Wenn du im Code die eine oder die andere Variante tippst, wird die Datenbank-Engine exakt denselben Ausführungsplan erstellen. Das Wort "Outer" ist in diesem speziellen Kontext optionales syntaktisches Rauschen, das weder die Performance noch das Ergebnis beeinflusst. Trotzdem klammern sich viele Entwickler an ihre Vorlieben, als ginge es um eine Glaubensfrage.
Die harte Wahrheit über Left Join vs Left Outer Join in SQL
Man muss die Dinge beim Namen nennen: In der Welt der relationalen Datenbanken wie PostgreSQL, MySQL oder Microsoft SQL Server ist das Schlüsselwort "Outer" lediglich eine Verdeutlichung für das menschliche Auge. Es gibt SQL-Dialekte, in denen die Syntax extrem streng ist, aber für die gängigen Systeme ist die Kurzform einfach nur eine Schreibersparnis.
Warum das Wort Outer überhaupt existiert
SQL wurde in den 1970er Jahren bei IBM entwickelt. Damals wollte man die Sprache so nah wie möglich an die englische Schriftsprache anlehnen. Man unterschied zwischen Inner Joins, die nur Treffer auf beiden Seiten anzeigen, und Outer Joins, die auch Zeilen beibehalten, für die es auf der gegenüberliegenden Seite keine Entsprechung gibt. Das "Outer" sollte klarmachen, dass wir uns außerhalb der reinen Schnittmenge bewegen. Wenn du heute eine Abfrage schreibst, weiß der Parser sofort, was gemeint ist, sobald das Wort "Left" fällt. Es kann technisch gar keinen "Left Inner Join" geben. Das wäre ein logischer Widerspruch. Deshalb ist die Langform heute eher ein Relikt für Puristen oder Leute, die ihren Code besonders explizit gestalten wollen.
Die Logik hinter der Verknüpfung
Stell dir vor, du hast eine Tabelle mit Kunden und eine mit Bestellungen. Nicht jeder Kunde hat schon etwas gekauft. Wenn du alle Kunden sehen willst, egal ob sie Geld ausgegeben haben oder nicht, greifst du zur linken Verknüpfung. Die linke Tabelle ist in diesem Fall dein Anker. Alles, was dort steht, landet im Ergebnis. Findet die Datenbank in der rechten Tabelle (den Bestellungen) keinen passenden Eintrag, füllt sie die Spalten einfach mit NULL auf. Das ist das ganze Geheimnis. Ob du dabei ein zusätzliches Wort in den Editor hämmerst, interessiert die CPU im Serverraum nicht im Geringsten.
Praktische Anwendung in der echten Welt
In meiner Zeit als Datenanalyst habe ich hunderte SQL-Skripte gesehen. Manche Firmen erzwingen per Styleguide die Langform. Andere Teams löschen jedes "Outer" sofort raus, um die Abfragen schlank zu halten. Wichtig ist nur, dass du verstehst, was unter der Haube passiert.
Das Problem mit verschwundenen Daten
Ein klassischer Fehler, der mir oft begegnet, passiert bei der Filterung in der WHERE-Klausel. Du machst eine saubere Verknüpfung von links nach rechts, um alle Datensätze zu behalten. Dann setzt du eine Filterbedingung auf eine Spalte der rechten Tabelle. Puff. Plötzlich fehlen die Zeilen, die eigentlich durch die linke Verknüpfung erhalten bleiben sollten. Das passiert, weil die Filterung nach dem Join stattfindet. Wenn in der rechten Spalte ein NULL-Wert steht und du nach einem spezifischen Wert filterst, fliegt der NULL-Eintrag raus. Hier hilft nur, die Bedingung direkt in den Join-Teil (hinter das ON) zu schreiben oder explizit auf NULL zu prüfen.
Performance Mythen und die Realität
Man hört oft, dass kürzere Befehle schneller verarbeitet werden. Das ist völliger Unsinn. Der Query Optimizer einer modernen Datenbank wie PostgreSQL zerlegt deinen Textbefehl in einen logischen Baum. Ob da nun fünf oder sechs Wörter stehen, macht im Parsvorgang Mikrosekunden aus, die in der Gesamtlaufzeit einer komplexen Abfrage völlig untergehen. Viel wichtiger als die Wahl der Syntax ist die Indexierung deiner Fremdschlüssel. Wenn auf den Spalten, über die du verknüpfst, kein Index liegt, wird jede Abfrage zur Qual, egal wie hübsch dein Code formatiert ist.
Strategien für saubere Datenbankabfragen
Guter Code zeichnet sich durch Lesbarkeit aus. Wenn du in einem Team arbeitest, solltest du dich an den bestehenden Standard halten. Konsistenz schlägt hier persönliche Vorlieben.
Die Bedeutung der Reihenfolge
Bei dieser Art der Verknüpfung ist die Reihenfolge der Tabellen entscheidend. Das unterscheidet sie massiv vom Inner Join. Tauscht du bei einer inneren Verknüpfung die Seiten, bleibt das Ergebnis gleich. Bei der hier besprochenen linken Variante ist das anders. Die Tabelle, die nach dem FROM kommt, ist die Basis. Alles, was nach dem Verknüpfungsbefehl steht, ist die Ergänzung. Wenn du merkst, dass du plötzlich "Right Joins" benutzt, solltest du kurz innehalten. In der Praxis liest man Code meist von links nach rechts. Ein Right Join zwingt das Gehirn zum Umdenken. Fast jeder erfahrene Entwickler wird dir raten: Drehe die Tabellen um und nutze stattdessen die linke Variante. Das hält den Fluss logisch.
Umgang mit großen Datenmengen
Wenn du Millionen von Zeilen verarbeitest, musst du vorsichtig sein. Eine Verknüpfung, die viele NULL-Werte produziert, kann den Speicher deines Clients sprengen, wenn du das Ergebnis exportierst. Ich habe einmal erlebt, wie ein unvorsichtiger Analyst eine riesige Nutzertabelle mit einer noch größeren Event-Log-Tabelle verknüpft hat. Da kein Limit gesetzt war und die Verknüpfung nicht sauber eingegrenzt wurde, lief der Server in ein Timeout. Solche Momente lehren dich, dass die Syntax zweitrangig ist, solange die Logik der Datenmenge nicht stimmt.
Warum die Unterscheidung Left Join vs Left Outer Join in SQL trotzdem in Interviews auftaucht
Es ist fast schon ein Klischee. Du sitzt im Vorstellungsgespräch für eine Stelle als Junior Developer und die Frage kommt: "Was ist der Unterschied?". Die richtige Antwort ist nicht, komplizierte Theorien aufzustellen. Die richtige Antwort ist: "Es gibt keinen funktionalen Unterschied, es ist dieselbe Operation." Damit zeigst du, dass du nicht nur auswendig gelernt hast, sondern die Sprache wirklich verstehst. Die Frage dient oft nur dazu, zu testen, ob ein Bewerber bei den Grundlagen sicher ist oder sich von Nuancen verunsichern lässt.
SQL Standards und die Geschichte
Der offizielle SQL-Standard wird von Organisationen wie der ISO definiert. In diesen Dokumenten wird oft die Langform verwendet, um die formale Korrektheit zu wahren. Die meisten Datenbankhersteller implementieren aber Abkürzungen, um das Leben der Entwickler zu erleichtern. Das ist vergleichbar mit anderen Programmiersprachen, in denen optionale Klammern oder Semikolons existieren. Es geht um Effizienz beim Tippen, ohne die Präzision der Maschine zu opfern.
Typische Fallstricke in der Praxis
Einer der nervigsten Fehler tritt auf, wenn man Tabellen über Spalten verknüpft, die unterschiedliche Datentypen haben. Die Datenbank versucht dann oft eine implizite Konvertierung. Das kann gut gehen, bremst aber die Geschwindigkeit massiv aus. Wenn du eine Tabelle mit Kunden-IDs als Text und eine mit IDs als Ganzzahl hast, wird der Join teuer. Hier hilft auch kein schöner Code, sondern nur ein sauberes Datenmodell. Ein weiterer Punkt ist die Duplizierung von Zeilen. Wenn die rechte Tabelle für einen Eintrag der linken Tabelle mehrere Treffer hat, vervielfältigt sich deine linke Zeile im Ergebnis. Das ist oft gewollt, kann aber bei Berechnungen wie Summen zu völlig falschen Zahlen führen.
Optimierung von Abfragen
Wer professionell mit Daten arbeitet, muss über den Tellerrand der reinen Syntax blicken. Die Struktur deiner Abfrage bestimmt, wie viel Last du dem System aufbürdest.
Den Ausführungsplan verstehen
Jedes Mal, wenn du eine Abfrage abschickst, erstellt die Datenbank einen Plan. Mit dem Befehl EXPLAIN kannst du dir diesen Plan ansehen. Dort siehst du genau, ob ein "Hash Join" oder ein "Nested Loop" verwendet wird. In diesen Plänen wirst du das Wort "Outer" oft gar nicht finden, weil die Maschine nur die logische Operation sieht. Es lohnt sich, diese Pläne regelmäßig zu studieren. Sie verraten dir mehr über die Effizienz deines Codes als jedes Tutorial.
Indizes und Statistiken
Datenbanken führen Statistiken über die Verteilung der Werte in den Spalten. Diese Informationen nutzt der Optimizer, um zu entscheiden, welche Tabelle er zuerst liest. Wenn diese Statistiken veraltet sind, wählt die Datenbank vielleicht einen ineffizienten Weg. In großen Umgebungen wie bei Oracle ist das Management dieser Statistiken ein Vollzeitjob für Administratoren. Für dich als Entwickler bedeutet das: Wenn eine Abfrage plötzlich langsam wird, liegt es selten an deinem Join-Befehl, sondern meist an den Daten darunter.
Die Wahl des richtigen Werkzeugs
SQL ist mächtig, aber man muss wissen, wann man welche Verknüpfung nutzt. Die linke Verknüpfung ist das Arbeitspferd der Datenanalyse. Sie ist sicher, weil sie keine Daten der Haupttabelle löscht.
Wann Inner Joins besser sind
Wenn du weißt, dass jeder Eintrag in der linken Tabelle zwingend ein Gegenstück in der rechten haben muss, nimm den Inner Join. Er ist psychologisch "enger" und zeigt klarer, dass hier eine harte Beziehung besteht. Außerdem vermeidest du so die mühsame Behandlung von NULL-Werten in deiner Anwendungslogik. Wer mit Java, Python oder C# auf die Datenbank zugreift, weiß, dass NULL-Werte oft zu Abstürzen führen, wenn man sie nicht explizit abfängt.
Die Gefahr von Cross Joins
Manchmal vergisst man die ON-Bedingung oder schreibt sie falsch. Das führt zu einem kartesischen Produkt. Jede Zeile der linken Tabelle wird mit jeder Zeile der rechten verknüpft. Bei kleinen Tabellen fällt das kaum auf. Bei großen Tabellen legt das den Server lahm. Das ist ein klassisches Szenario, in dem man sich wünscht, die Syntax wäre noch strenger. Aber SQL vertraut dem Benutzer.
Konkrete Tipps für den Alltag
Wenn du morgen wieder am Code arbeitest, probiere ein paar Dinge aus, um deine Arbeitsweise zu verbessern.
- Entscheide dich für einen Stil. Wenn du "Outer" schreiben willst, tu es konsequent. Wenn nicht, lass es überall weg.
- Prüfe deine ON-Bedingungen. Sind die Spalten indiziert? Haben sie denselben Datentyp?
- Nutze Aliase. Lange Tabellennamen machen Abfragen unleserlich. Verwende kurze, prägnante Kürzel wie 'k' für Kunden oder 'b' für Bestellungen.
- Teste mit kleinen Datenmengen. Bevor du die Abfrage auf die gesamte Datenbank loslässt, schau dir das Ergebnis mit LIMIT 10 an.
- *Vermeide SELECT . Benenne die Spalten, die du wirklich brauchst. Das reduziert die Datenlast und macht deinen Code robuster gegen Änderungen am Tabellendesign.
Es gibt im Grunde keinen Grund, sich über die Feinheiten der Benennung zu streiten. Wer versteht, dass die linke Tabelle dominiert und die rechte Tabelle optional Informationen beisteuert, hat das Wichtigste begriffen. Ob man nun die kurze oder die lange Variante bevorzugt, bleibt persönlicher Geschmack. Wichtig ist das Verständnis für die Datenstrukturen und die Auswirkungen auf die Performance.
Wer tiefer in die Materie einsteigen will, sollte sich mit den verschiedenen Join-Algorithmen beschäftigen. Es gibt Hash Joins, Merge Joins und Nested Loop Joins. Diese Begriffe beschreiben, wie die Datenbank die Zeilen tatsächlich physisch miteinander vergleicht. Das Wissen darüber ist für die Performance-Optimierung tausendmal wertvoller als die Kenntnis jeder optionalen Syntax-Variante.
Letztlich ist SQL eine Sprache, die uns helfen soll, Fragen an Daten zu stellen. Je klarer wir diese Fragen formulieren, desto besser sind die Antworten. Die linke Verknüpfung ist dabei eines der wichtigsten Werkzeuge in unserem Kasten. Sie erlaubt uns, Lücken in Daten zu finden, Berichte zu erstellen und Zusammenhänge zu verstehen, die sonst verborgen blieben.
Konzentriere dich auf die Logik. Baue saubere Indizes. Verstehe deine Daten. Wenn du diese drei Punkte beherrschst, ist es völlig egal, ob du "Outer" schreibst oder nicht. Dein Code wird funktionieren, er wird schnell sein und deine Kollegen werden ihn verstehen. Das ist es, was am Ende des Tages zählt, wenn die Reports pünktlich fertig sein müssen und der Server stabil laufen soll.
Nächste Schritte für dich
Gehe in deine aktuelle Codebase und schaue dir die am häufigsten genutzten Abfragen an. Prüfe mit dem EXPLAIN-Befehl, wie die Datenbank deine Verknüpfungen verarbeitet. Wenn du feststellst, dass viele Full Table Scans vorkommen, ist es Zeit für neue Indizes. Experimentiere auch mal mit der Platzierung von Filterbedingungen. Verschiebe eine Bedingung von der WHERE-Klausel in die ON-Klausel und beobachte, wie sich das Ergebnis verändert. Das ist der beste Weg, um ein echtes Gefühl für die Mechanik hinter den Kulissen zu bekommen. Nutze dieses Wissen, um deine Abfragen nicht nur schöner, sondern vor allem effizienter zu machen. Wer die Logik einmal verinnerlicht hat, den bringen auch kleine Syntax-Variationen nicht mehr aus der Ruhe. Viel Erfolg beim nächsten Query-Marathon.



