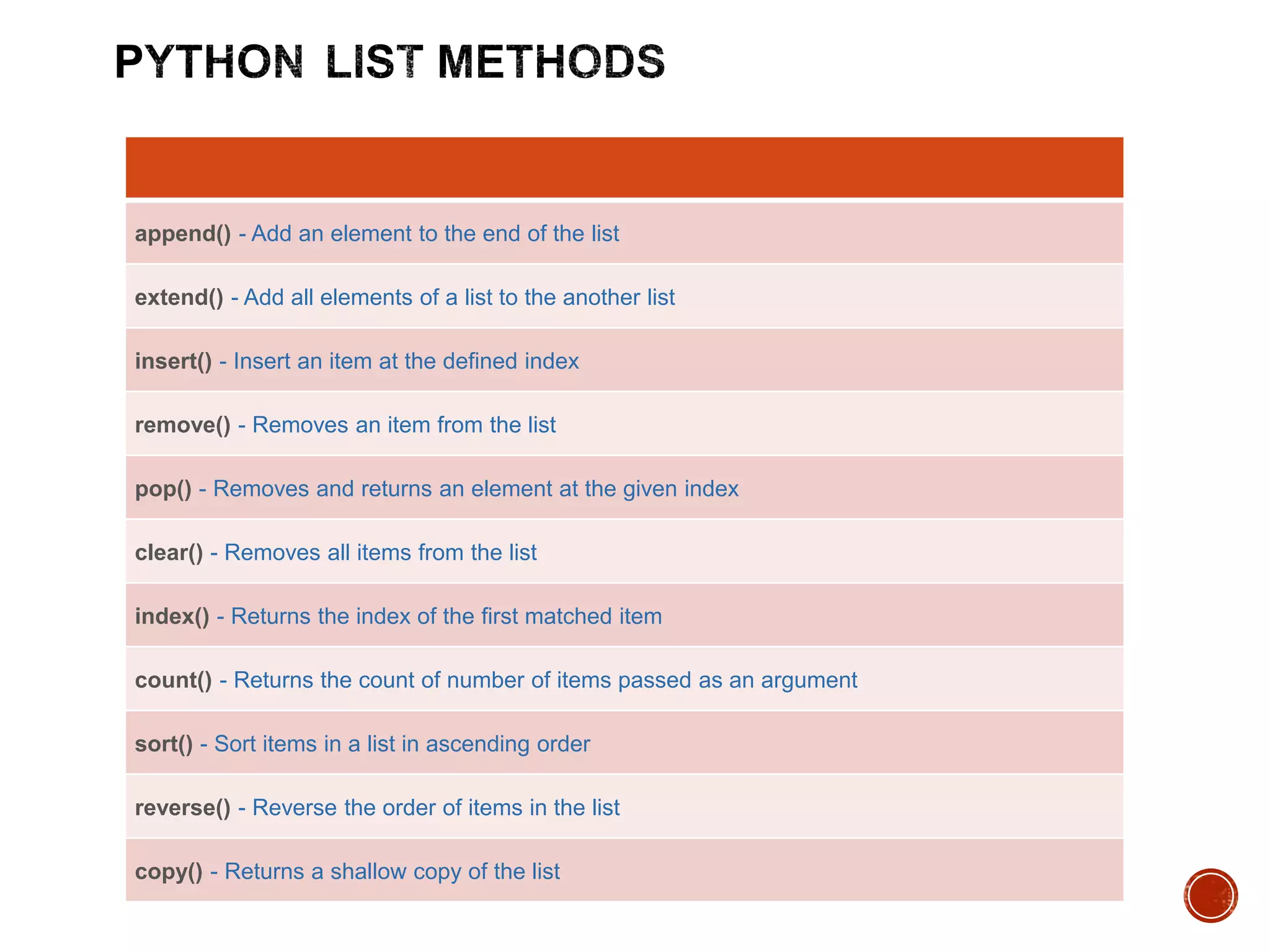
Die meisten Programmierer lernen Python, weil es ihnen verspricht, die Welt einfach abzubilden. Man fängt mit einer Liste an, packt ein paar Namen hinein, und wenn die Welt komplexer wird, legt man eben eine Liste in die Liste. Es fühlt sich intuitiv an. Es sieht aus wie eine Tabelle. Doch hier beginnt der schleichende Verfall der Code-Qualität, denn ein List Inside A List Python Konstrukt ist oft kein Zeichen von Struktur, sondern das Eingeständnis, dass man die Kontrolle über die Datenmodelle verloren hat. Wer Daten in tief verschachtelten Listen stapelt, baut kein Fundament, sondern ein Kartenhaus, das beim ersten Windstoß durch eine Typänderung oder eine neue Anforderung in sich zusammenbricht. In der professionellen Softwareentwicklung ist das blinde Vertrauen in diese Schachtelungen die Ursache für unzählige Nächte voller Fehlersuche, weil man am Ende vergisst, ob der Preis eines Artikels nun an Index zwei oder drei der inneren Liste steht.
Das Problem mit der unsichtbaren Struktur hinter List Inside A List Python
Wer zum ersten Mal Datenreihen verarbeitet, greift fast automatisch zu dieser Technik. Man stellt sich vor, wie die Daten sauber in Zeilen und Spalten liegen. Aber eine Liste in Python ist kein statisches Array, wie man es aus C oder Java kennt. Sie ist ein dynamisches Objekt, das Referenzen auf andere Objekte hält. Wenn wir dieses Feld der verschachtelten Strukturen betreten, geben wir die explizite Benennung unserer Daten auf. Wir tauschen sprechende Variablennamen gegen anonyme Ganzzahlen aus. Anstatt auf ein Attribut wie Preis zuzugreifen, greifen wir auf ein Element an Position vier zu. Das ist nicht nur unleserlich, es ist gefährlich. Wenn ein Kollege sechs Monate später eine neue Spalte in die Mitte der Datenquelle einfügt, bricht das gesamte Skript an Stellen, die mit der Änderung scheinbar nichts zu tun haben.
Ein erfahrener Entwickler sieht in einer solchen Struktur sofort das Risiko der impliziten Annahmen. Wir gehen davon aus, dass jede Unterliste exakt die gleiche Länge hat und dass die Datentypen an jeder Position identisch bleiben. Doch Python erzwingt das nicht. Python ist gnädig, bis es zu spät ist. Eine einzige Zeile, die aus einer Datenbank ein Feld weniger liefert, führt zu einem Index-Fehler, der mitten in einer kritischen Berechnung auftritt. Es gibt keinen Compiler, der uns warnt. Die vermeintliche Einfachheit entpuppt sich als technische Schuld, die wir mit jedem Index-Zugriff verzinsen. Ich habe Systeme gesehen, in denen Entwickler versuchten, diese Schwäche durch komplexe Kommentare zu heilen, in denen sie verzweifelt erklärten, was Index null bis neun bedeuten. Das ist der Moment, in dem man erkennen muss, dass man gegen die Sprache arbeitet, anstatt ihre Stärken für klare Datenstrukturen zu nutzen.
Warum List Inside A List Python die Performance heimlich auffrisst
Skeptiker werden nun einwenden, dass für kleine Datenmengen oder schnelle Prototypen der Aufwand, eine Klasse oder ein NamedTuple zu definieren, viel zu groß sei. Sie sagen, dass man für eine einfache Matrix keine Kanonen auffahren müsse. Doch genau hier liegt der Denkfehler. Die Performance-Einbußen bei tief verschachtelten Listen sind real und messbar. Jedes Mal, wenn du auf ein Element in einer List Inside A List Python Konstruktion zugreifst, muss der Interpreter zwei Zeiger auflösen. Zuerst sucht er die Adresse der äußeren Liste, dann springt er zur Adresse der inneren Liste, um dort den gewünschten Wert zu finden. Bei Millionen von Operationen summiert sich dieser Overhead massiv.
In der wissenschaftlichen Datenverarbeitung, wo Python dank Bibliotheken wie NumPy glänzt, würde niemand auf die Idee kommen, reine Python-Listen für Matrizen zu verwenden. Dort werden homogene Speicherbereiche genutzt, die der Prozessor effizient vorladen kann. Wenn wir stattdessen bei den Standard-Listen bleiben, zwingen wir den Python-Interpreter zu einem Zickzackkurs durch den Arbeitsspeicher. Die Daten liegen verstreut, die Cache-Lokalität ist katastrophal. Wer behauptet, Geschwindigkeit spiele bei Python ohnehin keine Rolle, verkennt, dass ineffizienter Code auch mehr Energie verbraucht und Hardware-Ressourcen unnötig bindet. Es geht nicht nur um Millisekunden, es geht um sauberes Handwerk.
Die kognitive Last der Verschachtelung
Man darf den menschlichen Faktor nicht unterschätzen. Unser Gehirn ist schlecht darin, sich mehr als zwei oder drei Ebenen der Abstraktion gleichzeitig vorzustellen, wenn diese keine Namen haben. Sobald wir eine dritte Ebene hinzufügen, wird der Code zu einer kryptischen Formel. Wir schreiben Zeilen, die wie Hieroglyphen aussehen. Wer versteht auf Anhieb, was ein Zugriff auf den dritten Index der fünften Liste innerhalb der zweiten Liste eigentlich fachlich bedeutet? Niemand. Wir zwingen den Leser des Codes, die gesamte Struktur im Kopf mitzuführen.
Das ist der Grund, warum moderne Python-Standards den Einsatz von Dataclasses oder einfachen Dictionaries mit festen Schlüsseln bevorzugen. Ein Dictionary gibt dem Wert einen Kontext. Ein Attribut einer Klasse gibt ihm eine Bedeutung. Wenn wir diese Klarheit opfern, nur um uns das Tippen von ein paar Zeilen Definition zu sparen, sabotieren wir die Wartbarkeit unseres eigenen Projekts. Ein guter Journalist hinterfragt die Quellen, ein guter Programmierer hinterfragt seine Bequemlichkeit. Die Bequemlichkeit, einfach alles in Listen zu stopfen, ist die Wurzel vieler Bugs, die erst in der Produktion sichtbar werden.
Die Arroganz der einfachen Lösung
Oft begegnet mir das Argument, dass komplexe Datenstrukturen den Code unnötig aufblähen würden. Man wolle schlanken Code schreiben. Das klingt erst einmal vernünftig. Aber Schlankheit darf nicht mit Unterernährung verwechselt werden. Code ist dann schlank, wenn er genau das ausdrückt, was er tut, ohne Rätsel aufzugeben. Eine verschachtelte Liste drückt gar nichts aus. Sie ist ein leerer Container. Sie sagt uns nicht, ob wir es mit Wetterdaten, Finanztransaktionen oder Nutzerprofilen zu tun haben.
Betrachten wir ein illustratives Beispiel aus der Praxis. Ein Team baute ein System zur Analyse von Sensorwerten. Sie speicherten alles in Listen. Es funktionierte. Dann kam ein neuer Sensor hinzu, der zwei statt drei Werte lieferte. Plötzlich stimmten die Indizes nicht mehr. Das System stürzte nicht sofort ab, es rechnete einfach falsch weiter, weil die falschen Zahlen in die falschen Formeln flossen. Es dauerte Wochen, bis der Fehler bemerkt wurde, weil der Code nach außen hin korrekt aussah. Hätte das Team von Anfang an auf Objekte gesetzt, wäre der Fehler beim Einlesen der Daten sofort aufgefallen. Die Weigerung, Struktur explizit zu machen, ist eine Form von technischer Arroganz, die davon ausgeht, dass man selbst niemals Fehler macht oder dass man sich ewig an jedes Detail des Codes erinnern wird.
Der Weg aus der Schachtelfalle
Wie kommen wir also weg von dieser schlechten Gewohnheit? Der erste Schritt ist die Erkenntnis, dass Python uns Werkzeuge an die Hand gibt, die weitaus mächtiger sind als einfache Container. Die Standardbibliothek bietet das Modul collections, in dem NamedTuples leben. Sie sind genauso effizient wie Listen, erlauben aber den Zugriff über Namen. Das macht den Code sofort lesbar. Wir müssen nicht mehr raten, was an Index eins steht. Wir lesen einfach den Namen.
Noch besser sind Dataclasses, die mit Python 3.7 eingeführt wurden. Sie erlauben es, Typen zu definieren und Validierungen einzubauen. Wenn wir eine Sammlung dieser Objekte haben, ist das immer noch eine Liste, aber der Inhalt ist klar definiert. Wir wissen genau, welche Form jedes Element hat. Das ist der Punkt, an dem Programmieren von der Bastelei zum Ingenieurswesen wird. Wir definieren Verträge zwischen verschiedenen Teilen unseres Programms. Ein Vertrag sagt: Ich liefere dir eine Sammlung von Objekten, die diese Eigenschaften haben. Eine verschachtelte Liste hingegen ist ein vages Versprechen, das jederzeit gebrochen werden kann.
Struktur als Selbstzweck vermeiden
Natürlich gibt es Situationen, in denen eine Liste von Listen sinnvoll ist, etwa bei mathematischen Matrizen, wenn man keine externen Abhängigkeiten wie NumPy einführen möchte. Aber das ist die Ausnahme, nicht die Regel. In neun von zehn Fällen ist die Entscheidung für dieses Feld der Verschachtelung eine Entscheidung gegen die Lesbarkeit. Wir müssen uns fragen, ob wir Code für den Computer schreiben oder für die Menschen, die ihn warten müssen. Der Computer versteht die Indizes problemlos. Der Mensch hingegen braucht Semantik.
Wir leben in einer Zeit, in der Software immer komplexer wird. Die Systeme, die wir heute bauen, werden morgen das Rückgrat von Unternehmen oder öffentlichen Diensten sein. Wir können es uns nicht leisten, diese Systeme auf einem Fundament aus anonymen Listen aufzubauen. Es ist eine Frage der professionellen Ethik, Code so zu gestalten, dass er nicht nur funktioniert, sondern auch verstanden werden kann. Die Einfachheit von Python ist eine Einladung, eleganten Code zu schreiben, keine Entschuldigung für Nachlässigkeit.
Wer heute noch glaubt, dass die maximale Verschachtelung von Standardcontainern ein Zeichen für effizientes Programmieren ist, hat den Übergang zur modernen Softwarearchitektur verpasst. Wahre Meisterschaft zeigt sich darin, die Komplexität der realen Welt so in Code zu übersetzen, dass die Struktur die Logik unterstützt, anstatt sie zu verbergen. Es ist an der Zeit, die Bequemlichkeit der Schachtelungen hinter uns zu lassen und Daten die Würde zu geben, die sie verdienen: einen Namen und eine klare Form.
Strukturlose Datenhaufen sind der stille Tod jeder langfristigen Softwarewartung.



