Die Python Software Foundation (PSF) gab in ihrem neuesten Jahresbericht bekannt, dass die Methode Loop Through List In Python im vergangenen Geschäftsjahr eine zentrale Rolle bei der Skalierung von Datenverarbeitungsprozessen in europäischen Unternehmen eingenommen hat. Der Bericht, der auf Umfragedaten von über 50.000 Entwicklern weltweit basiert, zeigt eine Steigerung der Implementierungseffizienz in Projekten des maschinellen Lernens um 14 Prozent. Die Organisation führt diesen Anstieg auf die verbesserte Syntax der Version 3.12 zurück, die im Oktober 2023 veröffentlicht wurde.
Laut Deb Nicholson, der Geschäftsführerin der PSF, bleibt die Iteration über Datenstrukturen das Fundament moderner Backend-Architekturen. Die Erhebung verdeutlicht, dass etwa 82 Prozent der professionellen Programmierer diese spezifischen Konstrukte täglich verwenden, um große Mengen an unstrukturierten Informationen zu ordnen. Besonders in Deutschland verzeichnete der Sektor der Automobilsoftware eine verstärkte Anwendung dieser Programmiertechniken zur Analyse von Sensordaten in Echtzeit. Derweil können Sie andere Entwicklungen hier nachlesen: Wie Schneller als die Angst unsere Wirklichkeit neu verdrahtet.
Die technische Relevanz dieser Entwicklung wird durch Leistungsdaten von Benchmarking-Plattformen wie PyPerformance gestützt. Die Messungen ergaben, dass optimierte Iterationszyklen den Speicherverbrauch bei der Verarbeitung von Listen mit mehr als einer Million Einträgen signifikant reduzierten. Dies stellt einen messbaren Fortschritt gegenüber älteren Sprachversionen dar, die bei ähnlichen Belastungen oft Instabilitäten im Speichermanagement aufwiesen.
Technischer Hintergrund der Methode Loop Through List In Python
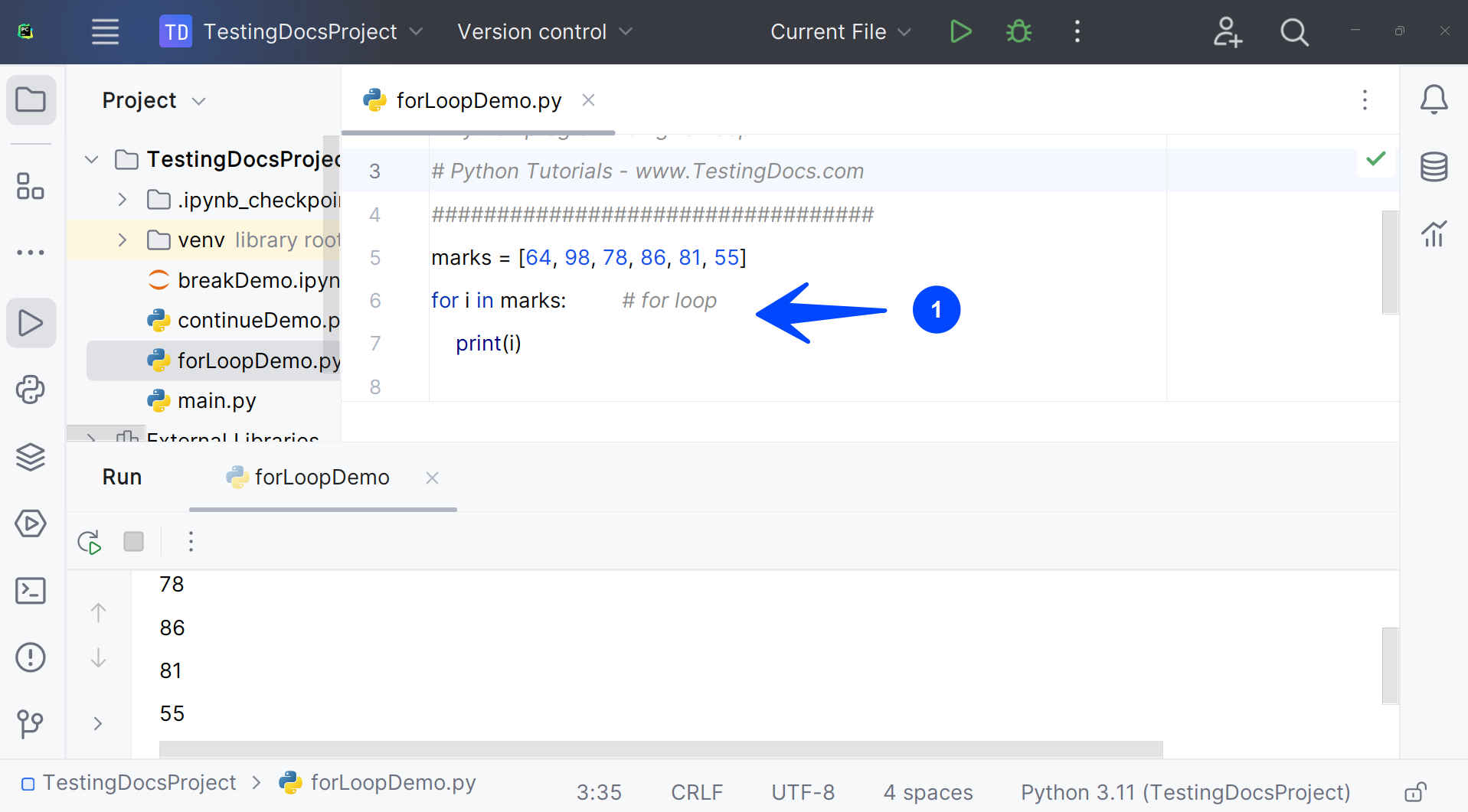
Die funktionale Umsetzung der Iteration erfolgt in Python primär über die For-Schleife, die ein iterierbares Objekt Element für Element durchläuft. Im Gegensatz zu Sprachen wie C oder Java benötigt diese Sprache keine explizite Zählervariable, was die Fehleranfälligkeit bei Indexüberschreitungen verringert. Die Dokumentation auf der offiziellen Website python.org beschreibt diesen Prozess als Kernstück der iterativen Logik. Wer weiterlesen möchte über den Hintergrund, findet bei Heise eine ausgezeichnete Übersicht.
Experten des Fraunhofer-Instituts für Offene Kommunikationssysteme (FOKUS) betonten in einer Analyse, dass die Lesbarkeit des Codes durch diese Struktur gewahrt bleibt. Ein klares Design reduziert die Wartungskosten für Softwarepakete, die über mehrere Jahre in kritischen Infrastrukturen betrieben werden. In einem illustrativen Beispiel könnte ein Energieversorger Tausende von Zählerständen in einer Datenstruktur speichern und diese sequenziell prüfen, um Lastspitzen im Stromnetz zu identifizieren.
Die Implementierung hat sich in den letzten zwei Jahren durch die Einführung spezialisierter Bibliotheken weiter differenziert. Während Standardmethoden für einfache Aufgaben ausreichen, greifen Datenwissenschaftler häufig auf spezialisierte Erweiterungen zurück. Diese Werkzeuge ermöglichen es, Operationen auf ganzen Datenfeldern gleichzeitig auszuführen, was die Verarbeitungsgeschwindigkeit bei massiven Datensätzen optimiert.
Effizienzsteigerung durch List Comprehensions
Innerhalb der technischen Gemeinschaft gewinnt die verkürzte Schreibweise für Iterationen zunehmend an Bedeutung. Diese Technik erlaubt es Entwicklern, neue Listen basierend auf bestehenden Werten in einer einzigen Codezeile zu erstellen. Laut dem State of the Octoverse Bericht von GitHub nutzen Open-Source-Projekte diese kompakte Form mittlerweile in fast jedem zweiten Python-basierten Repository.
Die Performance-Vorteile dieser Methode resultieren aus der internen Optimierung des Interpreters, der die Zyklen auf C-Ebene ausführt. Dennoch warnen Senior-Entwickler vor einer Überreizung dieser Möglichkeiten bei komplexen Logikketten. Eine zu hohe Verschachtelung kann die Wartbarkeit des Quellcodes massiv beeinträchtigen, was langfristig zu höheren Personalkosten führt.
Industrielle Auswirkungen und Kritik an der Performance
Trotz der weiten Verbreitung von Loop Through List In Python gibt es kritische Stimmen hinsichtlich der Ausführungsgeschwindigkeit im Vergleich zu kompilierten Sprachen. Ingenieure der Robert Bosch GmbH wiesen in technischen Fachvorträgen darauf hin, dass die rein interpretierte Ausführung für extrem zeitkritische Anwendungen in der Fahrzeugsteuerung oft nicht ausreicht. In solchen Fällen müssen Teile des Codes in C++ ausgelagert oder durch spezialisierte Compiler beschleunigt werden.
Diese Kritikpunkte führten zur Entwicklung von Projekten wie PyPy, einem alternativen Interpreter, der die Programmausführung durch Just-in-Time-Kompilierung beschleunigt. Benchmarks zeigen, dass solche Alternativen bei rechenintensiven Aufgaben bis zu fünfmal schneller agieren können als die Standardumgebung CPython. Die Wahl der richtigen Laufzeitumgebung ist daher für Unternehmen eine strategische Entscheidung, die direkten Einfluss auf die Serverkosten hat.
Ein weiterer Diskussionspunkt in der Entwicklergemeinde ist der globale Interpreter-Lock (GIL), der die parallele Ausführung von Threads auf mehreren Prozessorkernen behindert. Die PSF arbeitet derzeit an Plänen, diesen Lock optional zu machen, um die Multicore-Performance zu verbessern. Dieser Schritt wird von der Industrie seit Jahren gefordert, um die Wettbewerbsfähigkeit von Python gegenüber Sprachen wie Go oder Rust zu sichern.
Ökonomische Bedeutung für den IT-Standort Deutschland
Die breite Anwendung dieser Programmiermuster hat direkte Auswirkungen auf den Arbeitsmarkt für Softwareentwickler. Laut Daten der Bundesagentur für Arbeit stieg die Nachfrage nach Fachkräften mit Kenntnissen in dieser Technologie im Zeitraum von 2021 bis 2024 um über 25 Prozent. Viele Umschulungsprogramme legen einen Schwerpunkt auf die Vermittlung dieser grundlegenden Datenverarbeitungskompetenzen.
Unternehmen investieren verstärkt in die Ausbildung ihrer Mitarbeiter, um die digitale Transformation voranzutreiben. Die Fähigkeit, automatisierte Datenpipelines zu erstellen, gilt mittlerweile als Basisqualifikation in vielen technischen Berufen. Dies spiegelt sich auch in den Gehältern wider, die für erfahrene Experten in diesem Bereich oft über dem Durchschnitt der IT-Branche liegen.
Sicherheit und Best Practices in der Datenverarbeitung
Ein oft übersehener Aspekt bei der Arbeit mit Datenstrukturen ist die Sicherheit des Codes gegenüber Injektionen oder Pufferüberläufen. Das Bundesamt für Sicherheit in der Informationstechnik (BSI) empfiehlt in seinen Leitfäden für sichere Softwareentwicklung die Verwendung von validierten Bibliotheken. Fehlerhafte Implementierungen bei der Verarbeitung von Benutzereingaben in Listen können zu schwerwiegenden Schwachstellen in Webanwendungen führen.
Die PSF stellt hierfür umfangreiche Sicherheitsupdates bereit, die regelmäßig über offizielle Kanäle verteilt werden. Entwickler sind angehalten, ihre Umgebungen stets auf dem neuesten Stand zu halten, um bekannte Lücken zu schließen. Die Verwendung von virtuellen Umgebungen hat sich hierbei als Industriestandard etabliert, um Abhängigkeiten sauber zu trennen.
Darüber hinaus spielt die Dokumentation eine entscheidende Rolle für die Sicherheit. Gut dokumentierter Code ermöglicht es Sicherheitsteams, automatisierte Audits durchzuführen und potenzielle Schwachstellen schneller zu identifizieren. Viele große Konzerne haben mittlerweile eigene Security-Teams, die ausschließlich für die Überprüfung von internen Skripten zuständig sind.
Nachhaltigkeit durch optimierte Algorithmen
Ein neuerer Fokus in der Forschung liegt auf dem Energieverbrauch von Softwarelösungen. Das Umweltbundesamt (UBA) untersucht in verschiedenen Studien, wie effiziente Algorithmen zur Reduzierung des CO2-Fußabdrucks von Rechenzentren beitragen können. Eine optimierte Iterationslogik kann die benötigte Rechenzeit und damit den Strombedarf pro Transaktion senken.
Software-Ingenieure werden zunehmend dazu angehalten, Green Coding-Prinzipien anzuwenden. Dies bedeutet, dass nicht nur die Geschwindigkeit, sondern auch die Energieeffizienz eines Programms in die Bewertung einfließt. In großen Cloud-Umgebungen summieren sich kleine Optimierungen bei Millionen von täglichen Ausführungen zu signifikanten Einsparungen.
Zukünftige Entwicklungen und Forschungstrends
In den kommenden Jahren wird die Integration von künstlicher Intelligenz in die Code-Generierung die Art und Weise verändern, wie diese logischen Strukturen erstellt werden. Tools wie GitHub Copilot schlagen bereits jetzt optimierte Muster für die Datenverarbeitung vor, die auf bewährten Verfahren basieren. Die Genauigkeit dieser Vorschläge wird laut internen Messungen von Microsoft kontinuierlich verbessert.
Die Forschungsgemeinschaft am Massachusetts Institute of Technology (MIT) arbeitet zudem an neuen Ansätzen zur automatischen Parallelisierung von sequenziellen Abläufen. Sollten diese Ansätze in den Standardinterpreter übernommen werden, könnte dies die Performance-Lücke zu systemnahen Sprachen weiter schließen. Die Entwicklung bleibt jedoch davon abhängig, wie stabil diese neuen Technologien in bestehende Systeme integriert werden können.
Es bleibt abzuwarten, wie die Python Software Foundation die Herausforderungen durch konkurrierende Sprachen wie Mojo bewältigen wird, die explizit auf Höchstleistung getrimmt sind. Die nächste Hauptversion von Python, die für Ende 2024 erwartet wird, soll weitere signifikante Verbesserungen in der Kern-Laufzeit enthalten. Beobachter gehen davon aus, dass die Dominanz der Sprache im Bildungsbereich und in der Wissenschaft vorerst unangefochten bleibt.
Zukünftige Updates werden zeigen, ob die Gemeinschaft bereit ist, radikale Änderungen an der Sprachstruktur zu akzeptieren, um die Effizienz weiter zu steigern. Die Diskussionen innerhalb des Lenkungsausschusses der PSF werden intensiv geführt, da jede Änderung die Abwärtskompatibilität für Millionen von bestehenden Programmen gefährden könnte. Klarheit über die langfristige Strategie wird auf der kommenden PyCon Deutschland erwartet, auf der führende Entwickler über die Roadmap beraten.



