Jeder Anfänger lernt es in der ersten Stunde: Wer Text auf den Bildschirm bringen will, nutzt eine Funktion, die wie ein Fingerschnippen wirkt. Man gibt ein paar Zeichen ein, drückt die Eingabetaste, und die Magie passiert. Doch hinter der vermeintlichen Banalität von Printing New Line In Python verbirgt sich eine technische Altlast, die bis in die Ära der mechanischen Schreibmaschinen zurückreicht. Die meisten Entwickler glauben, sie würden lediglich einen vertikalen Sprung anweisen. In Wahrheit lösen sie eine komplexe Kette von Systemaufrufen und Puffer-Operationen aus, die über die Performance ganzer Serverfarmen entscheiden können. Wer das ignoriert, schreibt Code, der unter Last einknickt wie ein morsches Regal. Wir haben uns daran gewöhnt, die Oberfläche als die Realität zu akzeptieren, während der Maschinenraum darunter vor Komplexität ächzt.
Es ist eine weit verbreitete Fehlannahme, dass ein Zeilenumbruch nur ein unsichtbares Zeichen sei. Die Realität sieht anders aus. Wenn du heute ein Skript schreibst, das Millionen von Zeilen in eine Log-Datei pumpt, wird die Art und Weise, wie dieser Umbruch gesetzt wird, zum Flaschenhals. Es geht nicht nur darum, dass das Programm optisch Ordnung hält. Es geht um die Kommunikation mit dem Betriebssystem. Jedes Mal, wenn ein Standard-Print-Befehl abgesetzt wird, wartet das System im Hintergrund oft darauf, dass der Puffer geleert wird. Das kostet Zeit. Millisekunden addieren sich zu Minuten. In einer Welt, in der Hochfrequenzhandel und Echtzeit-Datenverarbeitung den Ton angeben, ist Ignoranz gegenüber diesen Mechanismen ein teurer Luxus. Ich habe Systeme gesehen, die allein deshalb fünfmal langsamer liefen als nötig, weil die Entwickler dachten, ein Zeilenumbruch sei eine rein ästhetische Entscheidung.
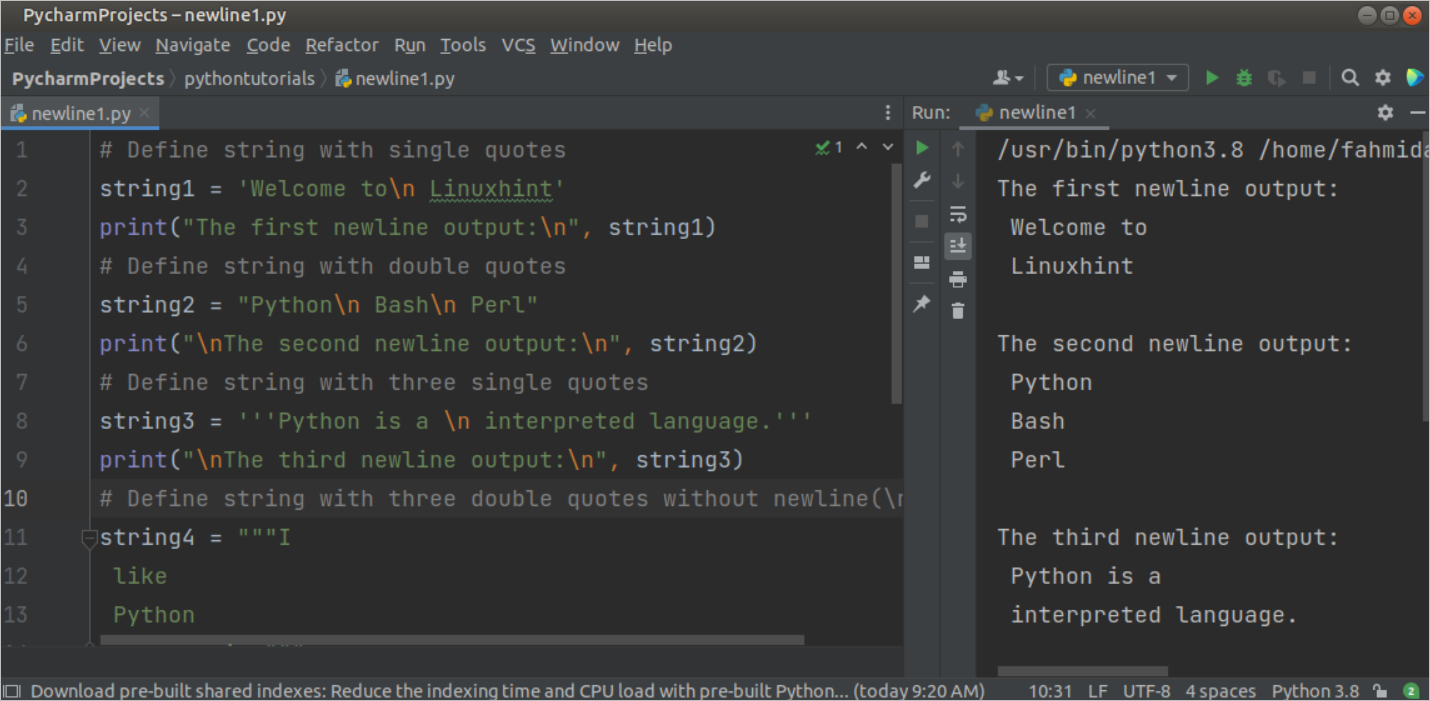
Die versteckte Mechanik hinter Printing New Line In Python
Wenn wir tief in die Eingeweide der Standardbibliothek blicken, stellen wir fest, dass die Flexibilität der Sprache einen Preis hat. Das System muss ständig prüfen, auf welcher Plattform es gerade läuft. Ein Unix-System verlangt nach einem Line-Feed, während alte Windows-Umgebungen noch immer dem Duo aus Carriage Return und Line Feed hinterhertrauern. Python versucht, diese Unterschiede durch das Konzept der universellen Zeilenumbrüche zu glätten. Das ist zwar komfortabel, aber es verschleiert die Tatsache, dass bei jedem Printing New Line In Python eine Übersetzung stattfindet. Diese Abstraktionsschicht ist der Grund, warum viele glauben, sie müssten sich nicht um die Details kümmern. Aber genau hier liegt die Falle.
Die Effizienz leidet besonders dann, wenn man die Standardeinstellungen unhinterfragt übernimmt. Die eingebaute Funktion fügt standardmäßig immer einen Umbruch am Ende hinzu. Das klingt logisch, führt aber dazu, dass viele Programmierer die Kontrolle über den Datenstrom verlieren. Sie senden kleine Häppchen an das Terminal oder die Datei, anstatt die Daten zu bündeln. Jedes Mal muss der Kernel des Betriebssystems geweckt werden, um die Schreiboperation zu bestätigen. Ein bewusster Verzicht auf den automatischen Umbruch und das manuelle Verwalten der Pufferung könnte die Geschwindigkeit massiv steigern. Es ist diese feine Linie zwischen dem Schreiben von funktionierendem Code und dem Schreiben von exzellentem Code, die den Fachmann vom Laien trennt.
Wer nun behauptet, dass moderne Hardware so schnell ist, dass diese Nuancen keine Rolle spielen, verkennt die Skalierbarkeit. Ein lokales Skript mag in einer Sekunde fertig sein. Ein Cloud-Dienst, der diese Operation milliardenfach pro Stunde ausführt, zahlt für diese Ineffizienz bares Geld in Form von Rechenzeit und Stromkosten. Es ist eine ökologische und ökonomische Frage, die im Kleinen beginnt. Wir müssen aufhören, den Zeilenumbruch als bloßes Formatierungswerkzeug zu betrachten. Er ist ein Steuersignal für den Datenfluss.
Die Illusion der Einfachheit
Die Dokumentation wirkt auf den ersten Blick klar. Ein Parameter hier, ein Escape-Zeichen dort. Doch wer hat sich wirklich mit den Unterschieden zwischen dem System-Standard und dem binären Schreiben auseinandergesetzt? Wenn man Daten binär schreibt, fällt die schützende Hand der Sprache weg. Plötzlich ist der Entwickler wieder in der Welt der 1970er Jahre gelandet, in der er jedes Byte einzeln verantworten muss. Das ist der Moment, in dem die meisten zurückweichen und sich in die Sicherheit der Standardfunktionen flüchten.
Ich erinnere mich an ein Projekt bei einem großen deutschen Automobilzulieferer, bei dem die Diagnose-Software ständig abstürzte. Das Problem war nicht die Logik der Datenverarbeitung. Es war die Art und Weise, wie Fehlermeldungen in die Konsole geschrieben wurden. Der Puffer lief voll, weil die Zeilenumbrüche nicht schnell genug verarbeitet werden konnten. Das System verbrachte mehr Zeit damit, den Cursor auf dem Bildschirm zu bewegen, als Berechnungen anzustellen. Nachdem wir die Ausgabe auf eine asynchrone Methode umgestellt hatten, verschwanden die Verzögerungen sofort. Es zeigt, dass selbst in hochmodernen Industriezweigen das Wissen um die Grundlagen der Ein- und Ausgabe oft sträflich vernachlässigt wird.
Warum Printing New Line In Python die Systemstabilität gefährdet
Ein weiteres unterschätztes Risiko ist die Fehlinterpretation von Dateiendungen und Formaten. Wenn verschiedene Systeme an derselben Datei arbeiten, führt ein falsch gesetzter Umbruch oft zu Fehlern, die tagelang gesucht werden. Ein Skript schreibt unter Linux, ein anderes liest unter Windows, und plötzlich erkennt der Parser die Struktur nicht mehr. Es ist kein Programmierfehler im klassischen Sinne, sondern ein Mangel an Weitsicht gegenüber der Umgebung. Wir verlassen uns zu sehr darauf, dass die Sprache alles für uns regelt. Doch Python ist kein Zauberstab, sondern ein Werkzeug.
Man könnte einwenden, dass moderne Editoren und IDEs diese Probleme automatisch korrigieren. Das ist jedoch eine gefährliche Sicherheit. Wer sich auf die Korrektur durch Tools verlässt, versteht den zugrunde liegenden Prozess nicht. Wenn der Code dann in einer minimalen Docker-Umgebung oder auf einem eingebetteten System ohne diese Komfortfunktionen läuft, bricht das Kartenhaus zusammen. Es ist die Pflicht eines professionellen Entwicklers, die vollständige Kontrolle über die Byte-Folge zu behalten, die sein Programm verlässt. Die Bequemlichkeit, die uns die High-Level-Programmierung bietet, darf nicht zur geistigen Trägheit führen.
Die Architektur des Datenstroms
Betrachten wir die Struktur eines Datenstroms als eine Autobahn. Jede neue Zeile ist wie eine Mautstelle. Wenn man jedes Auto einzeln anhält, entsteht ein Stau. Wenn man jedoch Gruppen von Autos durchwinkt, fließt der Verkehr. Viele unterschätzen, wie sehr das Betriebssystem optimieren kann, wenn man ihm die richtigen Signale gibt. Das bedeutet manchmal, den vertrauten Weg zu verlassen und sich mit den tieferen Schichten der I/O-Programmierung zu beschäftigen. Es erfordert Disziplin, die Ausgabe so zu strukturieren, dass sie sowohl für Menschen lesbar als auch für Maschinen effizient verarbeitbar ist.
Es gibt Stimmen, die sagen, man solle sich auf die Geschäftslogik konzentrieren und die Details der Ausgabe dem Framework überlassen. Das ist ein valider Punkt für einen Prototypen. Aber wer ein stabiles Produkt bauen will, kommt an den Details nicht vorbei. Ein erfahrener Journalist würde auch nicht behaupten, dass die Schriftart und der Zeilenabstand egal sind, solange die Wörter stimmen. Die Form beeinflusst die Aufnahme der Information, und beim Programmieren beeinflusst die technische Form der Ausgabe die Integrität des gesamten Systems.
Die Frage nach dem Zeilenumbruch ist letztlich eine Frage nach der Sorgfalt. Es geht darum, ob man den einfachsten Weg wählt oder den richtigen. In einer Branche, die von ständig neuen Frameworks und Trends getrieben wird, ist das Verständnis für solche fundamentalen Details ein Anker. Es bewahrt uns davor, immer wieder die gleichen Fehler zu machen. Wer versteht, wie ein Computer wirklich mit Text umgeht, wird automatisch besseren Code schreiben. Es ist Zeit, die Arroganz gegenüber den scheinbar gelösten Problemen abzulegen.
Man stelle sich vor, ein Bankensystem würde jede Transaktion einzeln mit einem grafischen Zeilenumbruch im Terminal bestätigen, während im Hintergrund die Warteschlange der Kunden wächst. Es klingt lächerlich, aber in abgeschwächter Form passiert genau das jeden Tag in tausenden von Anwendungen weltweit. Die Optimierung dieser Prozesse beginnt im Kopf des Programmierers, bevor er die erste Zeile Code tippt. Es ist die bewusste Entscheidung für Präzision statt für blinden Pragmatismus.
Skeptiker werden nun einwerfen, dass es Bibliotheken gibt, die all das für uns übernehmen. Natürlich gibt es die. Aber wer diese Bibliotheken nutzt, ohne ihre Funktionsweise zu begreifen, ist wie ein Autofahrer, der nicht weiß, wie man einen Reifen wechselt. Solange alles glatt läuft, ist es kein Problem. Doch sobald die Straße holprig wird, steht man hilflos am Rand. Ein tieferes Verständnis der Materie schützt vor unliebsamen Überraschungen in der Produktion.
Die Geschichte der Informatik ist voll von Beispielen, bei denen kleine Nachlässigkeiten zu großen Katastrophen führten. Ein falsches Zeichen in einer Konfigurationsdatei kann einen Satelliten zum Absturz bringen oder ein Kraftwerk lahmlegen. Auch wenn ein Zeilenumbruch selten so dramatische Folgen hat, ist er dennoch ein Symbol für die Genauigkeit, die wir unserem Handwerk schulden. Es gibt keinen unbedeutenden Code. Alles, was ausgeführt wird, hat eine Wirkung.
Letztendlich müssen wir uns fragen, welche Art von Systemen wir bauen wollen. Wollen wir Konstrukte, die gerade so funktionieren, oder wollen wir Meisterwerke der Effizienz? Der Weg zur Exzellenz führt über die Beschäftigung mit den Grundlagen. Das bedeutet auch, sich mit den scheinbar langweiligsten Themen wie der Zeichenkodierung und dem Stream-Handling auseinanderzusetzen. Wer diese Hürde nimmt, gewinnt eine neue Perspektive auf die Softwareentwicklung. Es ist eine Befreiung aus der Abhängigkeit von magischen Funktionen, die im Hintergrund Dinge tun, die man nicht versteht.
Wenn wir die Art und Weise, wie wir über Textausgabe denken, radikal ändern, verändert sich unser gesamter Ansatz zur Problemlösung. Wir fangen an, in Ressourcen zu denken. Wir sehen die CPU-Zyklen, den Speicherverbrauch und die Latenzzeiten, wo wir vorher nur Text gesehen haben. Das ist der Moment, in dem Programmieren von einer reinen Schreibarbeit zu einer Ingenieurskunst wird. Es ist ein Reifeprozess, den jeder durchlaufen sollte, der diesen Beruf ernst nimmt.
Die Beschäftigung mit diesem Thema zeigt uns auch, wie sehr wir von der Vergangenheit geprägt sind. Die Tatsache, dass wir heute noch über Carriage Returns diskutieren, ist ein direktes Erbe der mechanischen Ära. Es ist faszinierend und erschreckend zugleich, wie langlebig diese Konzepte sind. Es erinnert uns daran, dass wir in der Informatik nie auf einer grünen Wiese bauen. Wir bauen immer auf den Fundamenten derer auf, die vor uns kamen. Diese Fundamente zu kennen, ist keine Nostalgie, sondern eine Notwendigkeit für die Zukunft.
Die wirkliche Revolution in der Softwareentwicklung findet nicht in den neuesten Sprachfeatures statt, sondern in der Rückbesinnung auf handwerkliche Präzision bei jeder einzelnen Operation. Jedes Byte zählt. Jede Zeile zählt. Wer das verinnerlicht hat, braucht keine dicken Handbücher mehr, um zu wissen, was zu tun ist. Es wird zu einer intuitiven Klarheit, die sich durch das gesamte Projekt zieht. Und so wird aus einer kleinen technischen Randnotiz eine Philosophie des Bauens.
Ein Zeilenumbruch ist kein Ende, sondern eine bewusste Zäsur im endlosen Strom der Daten.



