Stell dir vor, du sitzt an einem Freitagabend im Büro. Dein Skript soll nur ein paar Millionen Einträge aus einer Datenbank bereinigen, bevor das Backup startet. Du hast dich für die intuitivste Methode entschieden, um Remove An Element From A List Python umzusetzen, und eine einfache Schleife geschrieben, die Elemente löscht, wenn sie eine bestimmte Bedingung erfüllen. Nach zwei Stunden merkst du: Das Skript wird nicht schneller, es wird langsamer. Viel langsamer. Was als Zehn-Minuten-Job geplant war, entwickelt sich zu einem Speicherfresser, der den Server in die Knie zwingt. Ich habe das oft erlebt. Entwickler, die glauben, dass eine Liste in Python wie ein flexibler Gummiband-Container funktioniert, stellen fest, dass sie bei falscher Handhabung eher wie ein Kartenhaus reagiert, das bei jeder Bewegung mühsam umgeschichtet werden muss. Ein einziger Logikfehler beim Löschen von Daten kann dich Stunden an Rechenzeit und im Cloud-Computing bares Geld kosten, wenn Instanzen unnötig lange laufen.
Die Falle der iterativen Löschung während der Laufzeit
Der wohl häufigste Fehler, den ich in Code-Reviews sehe, ist das Löschen von Elementen aus einer Liste, während man gleichzeitig über diese Liste iteriert. Es sieht im Code so sauber aus: for item in my_list: if condition: my_list.remove(item). Das Problem dabei ist, dass Python intern die Indizes verwaltet. Wenn du ein Element entfernst, rutschen alle nachfolgenden Elemente einen Platz nach vorne. Der Iterator merkt das nicht und springt zum nächsten Index, wodurch er prompt das Element überspringt, das gerade nachgerückt ist.
Das führt zu Bugs, die in kleinen Tests oft nicht auffallen, weil sie zufällig nur jedes zweite Element löschen, das eigentlich weg müsste. In einer Produktionsumgebung bedeutet das korrupte Datensätze. Wer so arbeitet, produziert technischen Abfall. Es gibt kein "vielleicht klappt es ja". Wenn du die Struktur unter den Füßen des Iterators wegziehst, fällst du hin. Punkt.
Warum Rückwärts-Iterieren auch keine Wunderwaffe ist
Einige schlaue Köpfe raten dazu, die Liste einfach von hinten nach vorne zu durchlaufen. Ja, das löst das Problem des Überspringens, weil die Indizes der Elemente, die du noch nicht besucht hast, unverändert bleiben. Aber es löst nicht das Performance-Problem. Jedes Mal, wenn du remove() aufrufst, muss Python die Liste linear durchsuchen, um den Wert zu finden, und dann alle Elemente dahinter physisch im Speicher verschieben. Bei einer Liste mit 100.000 Einträgen ist das Wahnsinn. Du zwingst den Prozessor zu Millionen von unnötigen Operationen.
Performance-Killer Remove An Element From A List Python und die lineare Suche
Viele unterschätzen die Zeitkomplexität. Die Methode .remove() hat eine Komplexität von $O(n)$. Das bedeutet, Python fängt vorne an zu suchen und geht jedes Element durch, bis es den Treffer landet. Wenn du das innerhalb einer Schleife machst, die selbst über die Liste läuft, landest du bei $O(n^2)$. Für einen Informatiker ist das das Todesurteil für jede Skalierbarkeit.
Ich erinnere mich an ein Projekt, bei dem ein Team versuchte, Duplikate aus einer Liste von 500.000 Nutzer-IDs zu entfernen, indem sie für jeden Eintrag prüften, ob er existiert, und ihn dann löschten. Das Skript lief über acht Stunden. Nachdem wir den Ansatz geändert hatten, dauerte es weniger als eine Sekunde. Der Fehler war nicht Python, der Fehler war das blinde Vertrauen in Standardmethoden ohne Verständnis für die Speicherverwaltung. Wer Remove An Element From A List Python als Allheilmittel sieht, hat die Grundlagen der Datenstrukturen nicht verstanden. Listen sind in Python eigentlich Arrays. Das Einfügen oder Löschen in der Mitte ist teuer.
Der Vorher-Nachher-Vergleich in der Praxis
Schauen wir uns ein reales Szenario an. Ein Entwickler möchte alle negativen Zahlen aus einer Liste von einer Million Messwerten entfernen.
Vorher (Der naive Weg):
Der Entwickler nutzt eine while-Schleife oder eine for-Schleife mit .remove(). Das Skript startet, die CPU-Last schießt auf 100 %, und der Speicher fängt an zu swappen. Da Python bei jedem Löschvorgang den Rest der Liste (im Schnitt 500.000 Elemente) im Speicher umkopieren muss, dauert jede einzelne Löschung Millisekunden. Bei 500.000 zu löschenden Elementen summiert sich das auf Stunden. Der Entwickler bricht das Skript nach 20 Minuten genervt ab, weil er denkt, der Server sei abgestürzt.
Nachher (Der Profi-Weg):
Anstatt die bestehende Liste zu verstümmeln, wird eine neue Liste per List Comprehension erstellt. new_list = [x for x in old_list if x >= 0]. Hier passiert etwas Magisches: Python geht die Liste genau einmal durch. Es gibt kein Suchen, kein Verschieben von Elementen im bestehenden Speicherblock. Die neue Liste wird effizient aufgebaut. Das gleiche Problem, das vorher Stunden dauerte, ist jetzt in etwa 0,05 Sekunden erledigt. Der Unterschied ist nicht marginal, er ist binär: Es funktioniert oder es funktioniert nicht für den professionellen Einsatz.
Missverständnisse bei der Identität und dem Wert
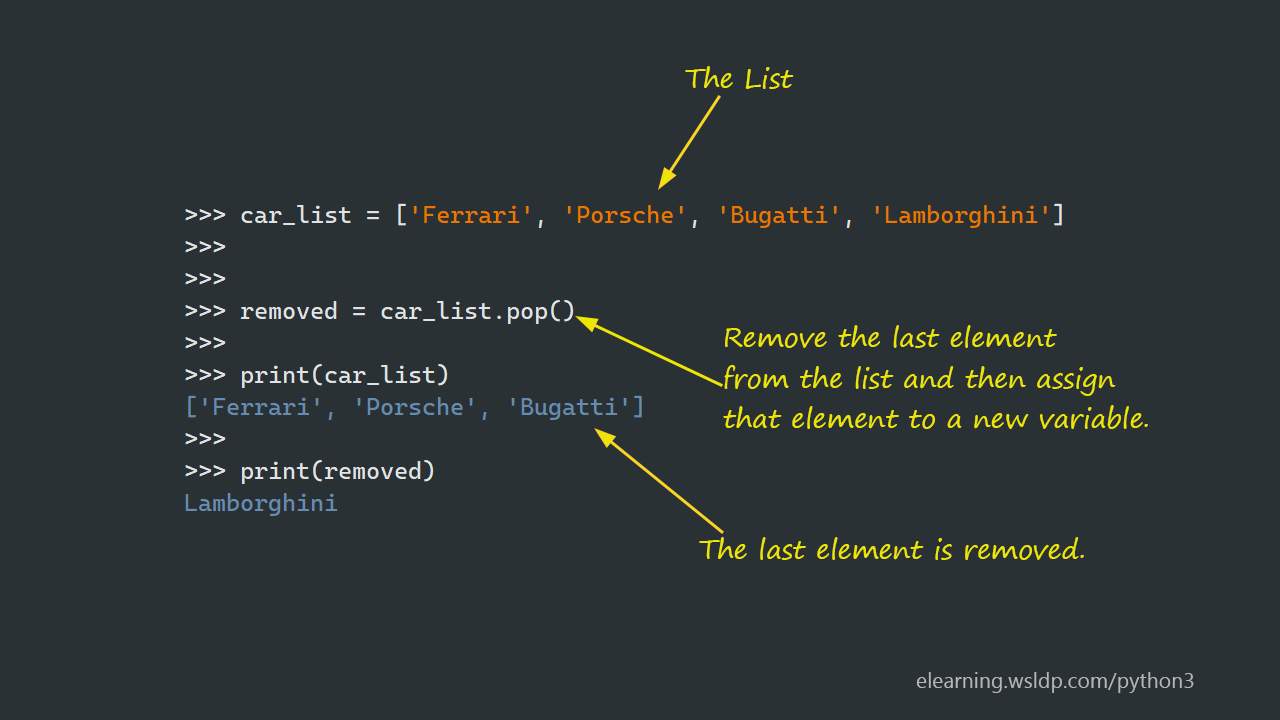
Ein weiterer Stolperstein ist der Unterschied zwischen del, pop() und remove(). Ich sehe oft, dass diese Begriffe synonym verwendet werden, was gefährlich ist.
dellöscht einen Index. Wenn du weißt, wo das Element ist, nimm das. Es ist schnell, erfordert aber, dass du den Index kennst.pop()gibt dir das Element zurück und löscht es am Index. Es ist ideal für Stacks, aber am Anfang einer Liste genauso langsam wie alles andere..remove()sucht nach dem ersten Vorkommen eines Wertes.
Wenn du versuchst, ein Objekt aus einer Liste zu löschen, das mehrfach vorkommt, löscht .remove() nur das erste. Wer denkt, er hätte damit "alle" Instanzen bereinigt, baut sich eine Zeitbombe. In einer Liste von Transaktionsdaten willst du vielleicht eine bestimmte ID löschen. Wenn diese ID aber durch einen Systemfehler zweimal auftaucht, bleibt eine Leiche im Keller liegen.
Speichermanagement und die Geister der gelöschten Objekte
In Python bedeutet "Löschen" nicht zwingend, dass der Speicher sofort frei wird. Python nutzt eine automatische Speicherbereinigung (Garbage Collection). Wenn du ein Element aus einer Liste entfernst, wird lediglich die Referenz in der Liste gelöscht. Wenn dieses Objekt noch woanders referenziert wird, bleibt es im RAM.
In großen Datenverarbeitungspipelins habe ich erlebt, dass Leute Listen "leeren", indem sie Element für Element löschen, aber die Liste selbst im Scope behalten. Das ist Unsinn. Wenn du den Speicher wirklich freigeben willst, setze die Liste auf None oder überschreibe sie mit einer leeren Liste [], sofern keine anderen Referenzen bestehen. Wer mühsam mit pop() eine Liste leert, verschwendet CPU-Zyklen für ein Ergebnis, das ein einfacher Zuweisungsbefehl in Nanosekunden erledigt hätte.
Warum Filter oft die bessere Wahl sind
Wenn man professionell mit Daten arbeitet, sollte man sich die filter() Funktion ansehen. Sie ist in C implementiert und oft einen Tick effizienter als eine List Comprehension, wenn es nur um das Aussortieren geht. Vor allem aber ist sie lesbarer für jemanden, der funktionales Programmieren gewohnt ist. Es geht darum, Absichten im Code klar auszudrücken. "Lösche das Element" ist eine Anweisung zur Manipulation. "Behalte nur diese Elemente" ist eine Definition des Zielzustands. Letzteres ist in der Programmierung fast immer sicherer.
Die Wahrheit über In-Place Operationen
Es gibt diesen Drang, Speicher zu sparen, indem man Dinge "in-place" erledigt. Das ist oft ein Trugschluss. In Python ist eine neue Liste oft effizienter als das Modifizieren einer bestehenden, es sei denn, die Liste ist so gigantisch, dass der Arbeitsspeicher faktisch voll ist. Aber in diesem Fall solltest du ohnehin nicht mit Python-Listen arbeiten, sondern mit numpy oder pandas.
Ich habe Teams gesehen, die tagelang versucht haben, Algorithmen zu optimieren, um Elemente innerhalb einer Liste zu verschieben und zu löschen, nur um zwei Megabyte RAM zu sparen. Gleichzeitig hat das Skript durch die schlechte Logik dreimal so lange gebraucht. Speicher ist billig, Entwicklerzeit und CPU-Stunden in der Cloud sind es nicht. In 99 % der Fälle ist das Erstellen einer gefilterten Kopie die einzig richtige Strategie.
Der Sonderfall: Sets für schnelles Löschen
Wenn die Reihenfolge keine Rolle spielt und du ständig Elemente entfernen und hinzufügen musst, ist eine Liste die falsche Datenstruktur. Ein set in Python basiert auf einer Hash-Tabelle. Das Löschen eines Elements aus einem Set hat eine Zeitkomplexität von $O(1)$. Das ist konstant, egal ob das Set zehn oder zehn Millionen Elemente hat.
Ein typisches Szenario aus meiner Praxis: Ein Abgleich von Sperrlisten. Wer hier eine Liste nutzt und jedes Mal prüft, ob eine ID vorhanden ist, um sie zu entfernen, hat schon verloren. Wer die Liste in ein Set umwandelt, macht den Prozess um den Faktor 1.000 schneller. Es ist wichtig, das Werkzeug dem Problem anzupassen, nicht das Problem dem Werkzeug.
Realitätscheck: Was du wirklich wissen musst
Kommen wir zum Punkt. Du willst Remove An Element From A List Python beherrschen? Vergiss die Lehrbücher, die dir nur die Syntax erklären. Die Syntax ist der einfache Teil. Die harte Wahrheit ist: Wenn du in Python mehr als ein paar hundert Elemente aus einer Liste löschen willst, ist der Standardweg über .remove() fast immer die falsche Wahl.
In der echten Welt der Softwareentwicklung geht es um Wartbarkeit und Geschwindigkeit. Ein Code, der zwar funktioniert, aber bei doppelter Datenmenge explodiert, ist schlechter Code. Ich habe gesehen, wie Karrieren stagnierten, weil Leute den Unterschied zwischen linearer und quadratischer Laufzeit nicht ernst genommen haben. Es wirkt wie Theorie, aber es ist das, was entscheidet, ob dein System unter Last stabil bleibt oder ob du am Wochenende Notfalleinsätze schieben musst.
Arbeite mit List Comprehensions. Nutze Sets für schnelle Lookups. Verstehe, dass Python unter der Haube Arrays schubst. Wenn du das akzeptierst, schreibst du Code, der nicht nur heute funktioniert, sondern auch dann noch, wenn dein Startup plötzlich zehnmal so viele Kunden hat. Alles andere ist Pfusch am Bau. Es gibt keine Abkürzung zum Verständnis deiner Datenstrukturen. Du musst wissen, was der Computer tun muss, wenn du ihm einen Befehl gibst. Nur dann hast du die Kontrolle. Es ist nicht schwer, es erfordert nur Disziplin und den Mut, die vermeintlich einfachen Lösungen zu hinterfragen, wenn sie nicht skalieren. Wer das ignoriert, zahlt später drauf – mit Zeit, Geld oder Nerven. So funktioniert das Geschäft nun mal.



