Ich stand vor drei Jahren in einem klimatisierten Serverraum in Frankfurt, während draußen die Mittagssonne brannte und drinnen die Stimmung am Gefrierpunkt war. Ein E-Commerce-Kunde hatte gerade seine Black-Friday-Zahlen aufgerufen, aber statt der erwarteten Echtzeit-Statistiken sah er nur ein sich drehendes Lade-Icon. Das Problem war hausgemacht. Ein Junior-Entwickler hatte versucht, die Verkäufe pro Kategorie mit SQL Count And Group By abzufragen, ohne zu ahnen, dass die Tabelle über Nacht auf 50 Millionen Zeilen angewachsen war. Die Datenbank war damit beschäftigt, temporäre Dateien auf die Festplatte auszulagern, weil der Arbeitsspeicher längst nicht mehr ausreichte. Was als einfacher Einzeiler begann, kostete das Unternehmen an diesem Nachmittag schätzungsweise 12.000 Euro an entgangenen Umsätzen, weil auch die Checkout-Prozesse durch die überlastete Datenbank blockiert wurden.
Die Illusion der Vollständigkeit bei NULL-Werten
Einer der häufigsten Fehler, die ich bei der Arbeit mit SQL Count And Group By sehe, ist das blinde Vertrauen in die Zählweise. Viele Leute glauben, dass COUNT(*) und COUNT(spaltenname) das gleiche Ergebnis liefern. Das ist ein Irrglaube, der in der Praxis zu falschen Geschäftsentscheidungen führt.
Wenn du COUNT(*) benutzt, zählt die Datenbank jede Zeile, egal was drinsteht. Nimmst du aber einen Spaltennamen, werden alle Zeilen ignoriert, in denen ein NULL-Wert steht. Ich habe erlebt, wie ein Marketing-Team dachte, sie hätten 10.000 aktive Kunden, dabei waren es 15.000. Die restlichen 5.000 hatten lediglich kein Geburtsdatum hinterlegt, und genau nach dieser Spalte wurde gezählt. Das ist kein technisches Detail, sondern ein logischer Abgrund. Wer Daten gruppiert, muss vorher wissen, wie das System mit der Abwesenheit von Daten umgeht. In einer sauberen Datenbank-Architektur sollten Pflichtfelder klar definiert sein, aber in der Realität der Altsysteme, mit denen wir uns täglich rumschlagen, ist das selten der Fall.
Performance-Killer durch falsche Indexierung bei SQL Count And Group By
Es ist ein weit verbreiteter Irrtum, dass Indizes nur für WHERE-Klauseln gut sind. Wenn du Daten gruppierst, muss die Datenbank die Werte sortieren oder in einem Hash-Table organisieren, um die Gruppen überhaupt bilden zu können. Ohne den richtigen Index auf den Spalten, die du in der Gruppierung verwendest, zwingst du das System zu einem sogenannten Full Table Scan.
Der Unterschied zwischen Heap und Index
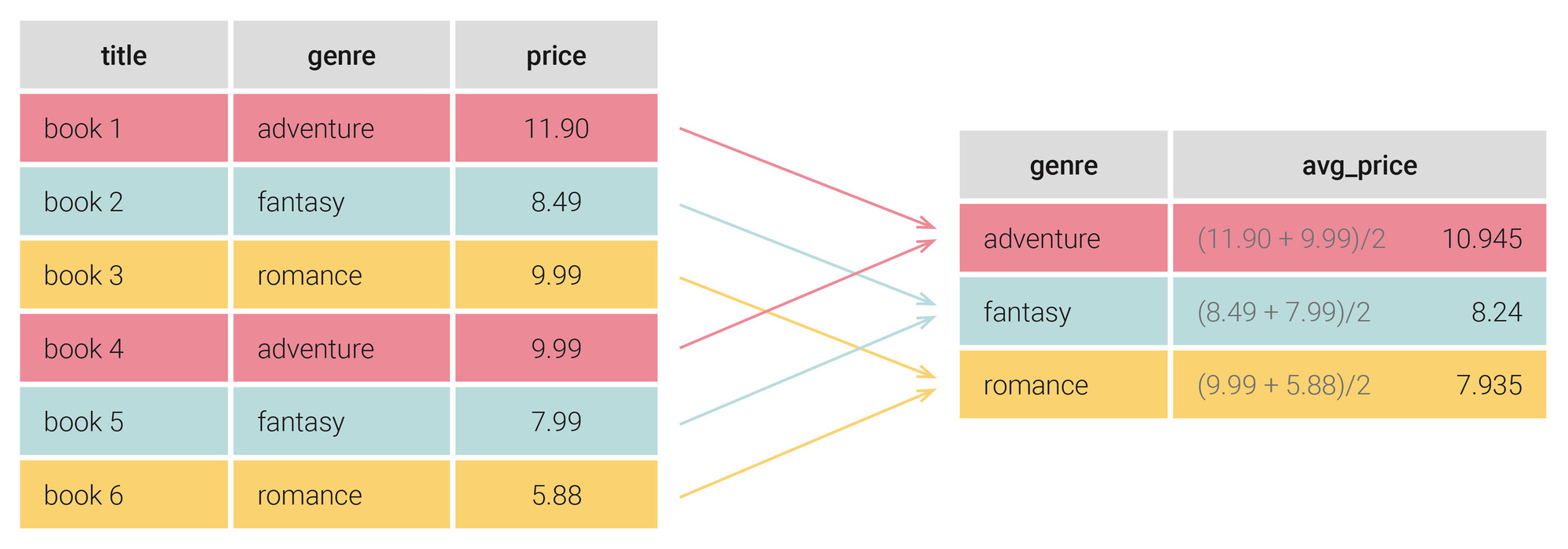
Stell dir vor, du hast eine Bibliothek ohne Sortierung. Wenn ich dich frage, wie viele Bücher jedes Genre hat, musst du jedes einzelne Buch in die Hand nehmen. Das ist das, was passiert, wenn du ohne Index arbeitest. Ein Index ist wie ein vorsortiertes Verzeichnis. Die Datenbank springt direkt zu den Startpunkten der Gruppen. In dem Szenario in Frankfurt war genau das das Problem: Die Gruppierung erfolgte über eine Textspalte ohne Index. Die CPU-Last sprang auf 100 Prozent, nur um Texte zu vergleichen, die sich eigentlich nie änderten.
Warum Kardinalität dein Schicksal bestimmt
Ein technischer Aspekt, den viele ignorieren, ist die Kardinalität. Wenn du nach einer Spalte gruppierst, die fast nur eindeutige Werte enthält – wie zum Beispiel eine Zeitmarke auf die Millisekunde genau –, dann wird die Gruppierung extrem langsam und das Ergebnis ist obendrein nutzlos. Du hast dann fast so viele Gruppen wie Zeilen. In solchen Fällen ist es klüger, die Daten vorher zu runden oder zu kappen, bevor die Gruppierung überhaupt angefasst wird.
Das Filtern an der falschen Stelle kostet Zeit
Ein Fehler, der immer wieder auftaucht, ist die Verwechslung von WHERE und HAVING. Ich sehe oft Abfragen, die versuchen, Millionen von Zeilen erst zu gruppieren und dann mit HAVING auszusortieren. Das ist pure Verschwendung von Rechenleistung.
Die Regel ist simpel: Alles, was du vor der Gruppierung rausschmeißen kannst, gehört in die WHERE-Klausel. Wenn du nur die Verkäufe von 2024 zählen willst, dann filtere das Jahr 2024 heraus, bevor die Datenbank auch nur einen Gedanken an das Zählen verschwendet. HAVING ist ausschließlich dafür da, Ergebnisse der Aggregation zu filtern – zum Beispiel: "Zeig mir alle Kategorien, die mehr als 500 Verkäufe haben." Wer das verwechselt, schickt seine Datenbank auf einen unnötigen Marathon. In einem konkreten Fall reduzierte der Wechsel von einem falsch platzierten Filter zu einer korrekten WHERE-Bedingung die Abfragezeit von 14 Sekunden auf unter 200 Millisekunden.
Vorher und Nachher: Ein Blick in die Realität der Optimierung
Um zu verstehen, wie tiefgreifend diese Fehler sind, schauen wir uns einen typischen Fall aus meiner Praxis an. Ein Logistikunternehmen wollte wissen, wie viele Pakete pro Depot im Verzug sind.
Der falsche Ansatz:
Der Entwickler schrieb eine Abfrage, die alle Sendungen der letzten fünf Jahre lud. Er gruppierte nach der Depot-ID und berechnete die Differenz zwischen Soll- und Ist-Lieferdatum direkt in der Gruppierung. Weil er COUNT(lieferdatum) nutzte, fielen alle Pakete raus, die noch unterwegs waren (da sie noch kein Lieferdatum hatten). Das Ergebnis war eine Tabelle, die völlig normale Werte anzeigte, während draußen die Kunden wegen verspäteter Lieferungen Sturm liefen. Die Abfrage dauerte knapp 40 Sekunden, da die Berechnung für jede der 12 Millionen Zeilen während der Gruppierung durchgeführt wurde.
Der richtige Ansatz:
Zuerst haben wir den Zeitraum in der WHERE-Klausel auf die letzten 30 Tage begrenzt – das allein eliminierte 90 % der Daten. Dann haben wir einen Index auf die Depot-ID und den Status gesetzt. Statt einer komplexen Berechnung innerhalb der Zählung haben wir einfach nur die Zeilen gezählt, deren Status-Flag auf "Verspätet" stand. Die Abfrage nutzte COUNT(*), um sicherzustellen, dass kein Paket vergessen wurde. Das Ergebnis war nach 0,5 Sekunden da und zeigte die bittere Wahrheit: Drei Depots waren völlig überlastet. Der Unterschied lag nicht in der Hardware, sondern in der Logik, wie die Daten angefasst wurden.
Gruppierung über mehrere Tabellen hinweg
Wenn du Joins mit einer Gruppierung kombinierst, begibst du dich auf dünnes Eis. Das ist der Moment, in dem die gefürchteten Duplikate entstehen. Wenn du eine Tabelle "Kunden" mit einer Tabelle "Bestellungen" verknüpfst und dann die Kunden zählst, erhältst du nicht die Anzahl der Kunden, sondern die Anzahl der Verknüpfungen.
Ich habe Berater gesehen, die völlig falsche Provisionszahlungen berechnet haben, weil sie durch Joins die Anzahl der Abschlüsse künstlich aufgebläht hatten. Die Lösung hier ist oft die Verwendung von COUNT(DISTINCT spaltenname), aber Vorsicht: DISTINCT ist extrem teuer für die Performance. Es erfordert einen weiteren Sortiervorgang im Speicher. Oft ist es besser, mit Unterabfragen (Subqueries) zu arbeiten, die die Daten erst auf einer Ebene aggregieren, bevor sie mit der nächsten Tabelle verknüpft werden. Das hält die Datenmengen klein und die Logik sauber.
Die Falle der impliziten Sortierung
In älteren SQL-Dialekten oder bestimmten Konfigurationen führte eine Gruppierung automatisch zu einer Sortierung der Ergebnisse. Viele Entwickler verlassen sich auch heute noch darauf. Aber moderne SQL-Engines garantieren keine Sortierung mehr, es sei denn, du schreibst explizit ORDER BY.
Es ist mir schon passiert, dass ein automatisierter Report jahrelang funktionierte und nach einem Datenbank-Update plötzlich völlig unsinnige Reihenfolgen ausgab. Verlasse dich niemals auf das Standardverhalten einer Engine bei der Nutzung von SQL Count And Group By. Wenn die Reihenfolge für deinen Bericht wichtig ist, dann schreib sie hin. Das kostet kaum zusätzliche Zeit, da die Daten durch die Gruppierung ohnehin schon oft im Speicher sortiert vorliegen, aber es sichert dich gegen zukünftige Updates ab.
Datentypen und ihre Tücken bei der Aggregation
Ein technischer Punkt, der oft übersehen wird: Die Größe der Datentypen in der gruppierten Spalte. Wenn du nach einer VARCHAR(255) Spalte gruppierst, in der eigentlich nur kurze Ländercodes stehen, verschwendest du Ressourcen. Die Datenbank muss bei jedem Vergleich viel mehr Bytes prüfen, als eigentlich nötig wären.
In einem Projekt für einen Zahlungsdienstleister haben wir die Gruppierungsspalten von langen Texten auf Integer-IDs umgestellt. Die Performance-Steigerung war massiv. Zahlenvergleiche sind für eine CPU nativ und blitzschnell; Textvergleiche hängen von Kollationen, Zeichensätzen und Längen ab. Wer auf Performance angewiesen ist, gruppiert niemals nach langen Freitextfeldern. Wenn es sein muss, dann berechne vorher einen Hash-Wert und gruppiere danach, aber vermeide rohen Text in großen Mengen.
Realitätscheck
Kommen wir zum Punkt: SQL ist kein Zauberstab. Die Vorstellung, dass man einfach jede beliebige Menge an Daten mit ein paar Befehlen in Echtzeit analysieren kann, ist ein Märchen, das uns Software-Verkäufer gerne erzählen. In der echten Welt stößt du bei der Arbeit mit Aggregationen sehr schnell an physikalische Grenzen.
Wenn deine Tabelle mehr als ein paar Millionen Zeilen hat, ist der klassische Weg oft am Ende. Du musst dann über Materialized Views, OLAP-Würfel oder vorberechnete Summentabellen nachdenken. Es ist keine Schande zuzugeben, dass eine Live-Abfrage zu langsam ist. Die Profis, die ich kenne, verbringen 20 % ihrer Zeit mit dem Schreiben der Abfrage und 80 % mit der Optimierung der Datenstruktur darunter.
Erfolg in diesem Bereich bedeutet nicht, die kompliziertesten SQL-Befehle zu kennen. Es bedeutet zu verstehen, wie die Daten auf der Festplatte liegen und wie viel Arbeit du der CPU zumuten kannst. Wer glaubt, er könne schlechtes Datenbankdesign durch "clevere" Abfragen retten, wird früher oder darauffolgend scheitern – meistens dann, wenn es gerade am teuersten ist. Kluge Entwickler bauen ihre Systeme so, dass die Gruppierung so wenig Arbeit wie möglich hat. Alles andere ist nur das Verschieben von Problemen, bis der Server irgendwann streikt.



