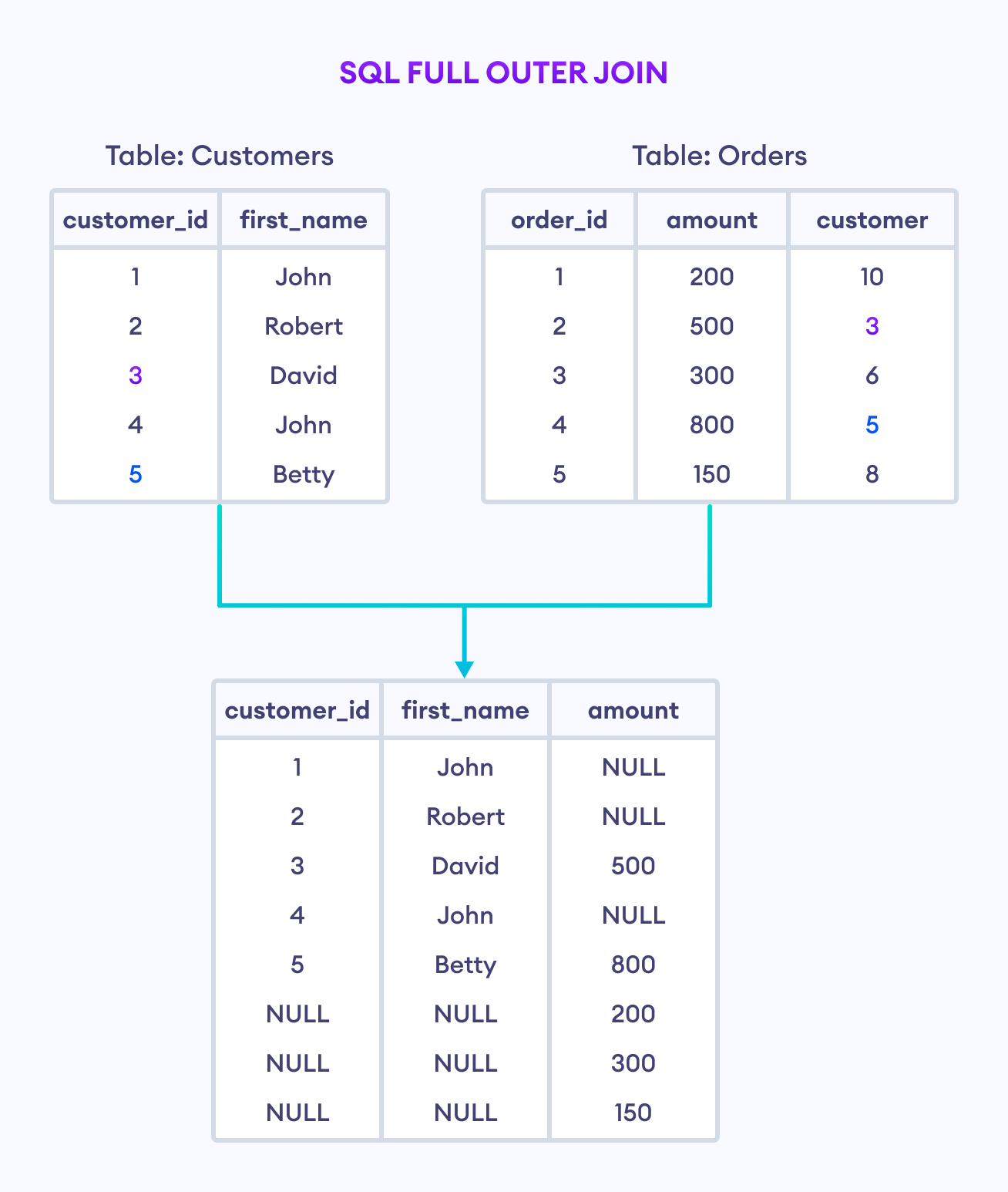
Du kennst das Problem sicher aus deinem Arbeitsalltag mit Datenbanken. Du hast zwei Tabellen, die eigentlich zusammengehören, aber in der Realität klaffen Lücken. In der einen Liste stehen alle deine Kunden, in der anderen nur die Bestellungen, die sie in der letzten Woche getätigt haben. Wenn du jetzt einen Standard-Join machst, fliegen alle Kunden raus, die nichts gekauft haben. Das ist fatal für Marketingberichte oder Bestandsanalysen. Genau hier rettet dir SQL Join Left Outer Join den Hintern, weil diese Abfrageform sicherstellt, dass deine Hauptliste vollständig bleibt, egal wie lückenhaft die verknüpfte Tabelle sein mag. Ich habe schon oft erlebt, wie Entwickler verzweifeln, weil ihre Berichte plötzlich geschrumpft sind, nur weil sie die Mechanik hinter dieser speziellen Verknüpfung nicht verstanden haben.
Die Logik hinter der linken Außenseite
Die Grundidee ist simpel, aber mächtig. Stell dir vor, du hast eine linke Seite – deine Basis – und eine rechte Seite, die Zusatzinfos liefert. Bei dieser Verknüpfung sagt der SQL-Server: Nimm auf jeden Fall alles von links mit. Wenn rechts etwas Passendes liegt, klebe es dran. Wenn rechts gähnende Leere herrscht, fülle die Spalten einfach mit Nullwerten auf. Das klingt nach einer Kleinigkeit, macht aber den Unterschied zwischen einem korrekten Dashboard und völligem Daten-Chaos. Wer Datenbanken effektiv abfragen will, muss diese Priorisierung beherrschen. Es geht nicht nur um das Verbinden von Zeilen, sondern um den Erhalt der Datenintegrität deiner Primärquelle.
Die praktische Anwendung von SQL Join Left Outer Join im Berufsalltag
In der Theorie sieht das oft trocken aus, doch in der Praxis am SQL Server oder bei einer MySQL-Instanz entscheidet dieser Befehl über Erfolg oder Misserfolg. Denke an ein CRM-System. Du willst eine Liste aller registrierten Nutzer und daneben sehen, wann ihr letzter Login war. Viele Nutzer haben sich vielleicht seit der Registrierung nie wieder eingeloggt. Nutzt du einen normalen Inner Join, verschwinden diese inaktiven Nutzer komplett aus deiner Ergebnismenge. Dein Chef denkt dann, ihr hättet nur halb so viele User, wie eigentlich in der Datenbank stehen. Das ist ein klassischer Fehler, der durch den gezielten Einsatz der linken Verknüpfung vermieden wird.
Warum Nullwerte dein bester Freund sind
Viele Anfänger haben Angst vor Nullwerten in ihren Ergebnissen. Ich sage: Lerne sie zu lieben. Ein Nullwert in der rechten Spalte einer solchen Abfrage liefert dir eine wertvolle Information. Er sagt dir explizit, dass zu diesem Datensatz keine Entsprechung existiert. In einem Onlineshop bedeutet ein Nullwert in der Spalte "Versanddatum", dass dieser Auftrag noch gar nicht bearbeitet wurde. Wenn du diese Information durch einen falschen Join-Typ unterdrückst, verlierst du die Sichtbarkeit auf deine Rückstände. Das Ziel ist nicht immer eine perfekt gefüllte Tabelle, sondern ein ehrliches Abbild der Datenlage.
Performance und Indizierung beachten
Man darf nicht vergessen, dass jede Verknüpfung Rechenleistung kostet. Wenn du eine Tabelle mit Millionen von Kunden gegen eine Tabelle mit Milliarden von Log-Einträgen prüfst, wird die Datenbank ins Schwitzen kommen. Hier ist es wichtig, dass die Spalten, über die du die Verknüpfung herstellst, ordentlich indiziert sind. Meistens ist das die ID des Kunden oder eine andere Primärschlüssel-Spalte. Ohne Index muss die Datenbank einen Full Table Scan machen. Das dauert ewig. Ich habe schon Abfragen gesehen, die statt drei Sekunden plötzlich fünf Minuten liefen, nur weil jemand vergessen hatte, den Fremdschlüssel zu indizieren.
Syntax und Fallstricke bei SQL Join Left Outer Join
Die Schreibweise ist in den meisten SQL-Dialekten identisch, egal ob du PostgreSQL, Oracle oder Microsoft SQL Server nutzt. Das Wort "Outer" ist dabei oft optional. Man kann es schreiben, um den Code lesbarer zu machen, aber "Left Join" allein bewirkt technisch genau dasselbe. Es ist eine Frage des Stils. Ich persönlich schreibe es gerne aus, wenn ich in einem Team arbeite, wo nicht jeder ein SQL-Profi ist. So wird sofort klar, dass hier keine Daten der linken Tabelle verloren gehen dürfen.
Den Unterschied zum Right Join verstehen
Theoretisch könnte man fast jede Abfrage auch als Right Join schreiben, indem man einfach die Reihenfolge der Tabellen vertauscht. Aber mal ehrlich: Wer macht das? Unser Gehirn liest von links nach rechts. Es ist viel natürlicher, die wichtigste Tabelle zuerst zu nennen und dann weitere Informationen von rechts "anzustechen". Ein Right Join wirkt im Code oft wie ein Rückwärtseinparken in einer Einbahnstraße. Es funktioniert, wirkt aber unnatürlich und macht den Code schwerer wartbar. Bleib bei der linken Variante, das ist Industriestandard und sorgt für weniger Stirnrunzeln bei deinen Kollegen.
Filterung in der Where-Klausel vs On-Klausel
Das ist der Punkt, an dem die meisten Leute stolpern. Wenn du Bedingungen hast, die die rechte Tabelle betreffen, musst du höllisch aufpassen. Packst du einen Filter für die rechte Tabelle in die Where-Klausel, wird dein Left Join faktisch zu einem Inner Join degradiert. Warum? Weil die Where-Klausel die bereits verknüpften Daten filtert. Da ein Nullwert keinen Vergleichstest wie "Preis > 100" bestehen kann, fliegen alle Zeilen ohne Treffer wieder raus. Wenn du die Vollständigkeit der linken Seite erhalten willst, müssen solche Bedingungen direkt in die On-Klausel der Verknüpfung. Das ist ein feiner Unterschied mit massiven Auswirkungen.
Komplexe Szenarien mit mehreren Verknüpfungen
In der Realität bleibt es selten bei zwei Tabellen. Oft verknüpfst du eine Kette von fünf oder sechs Tabellen. Hier wird es richtig spannend. Wenn du einmal mit einer linken Außenseite anfängst, musst du oft bei den folgenden Verknüpfungen in der Kette dabei bleiben. Sobald du einen Inner Join nach einem Left Join einbaust, besteht die Gefahr, dass du die "aufgefüllten" Zeilen wieder verlierst. Man muss die Datenverarbeitung wie eine Pipeline betrachten. Was einmal links rausgefallen ist, kriegst du später nur schwer wieder rein, ohne die Logik zu verbiegen.
Das Problem der Duplikate
Ein häufiges Ärgernis sind eins-zu-viele Beziehungen. Wenn ein Kunde zehn Bestellungen hat, erscheint der Kunde in deinem Ergebnis zehnmal. Viele Anfänger wundern sich dann, warum ihre Kundenliste plötzlich so lang geworden ist. Hier hilft kein anderer Join-Typ, sondern eine Aggregation oder ein DISTINCT. Du musst wissen, was dein Ziel ist. Willst du eine Liste von Kunden oder eine Liste von Transaktionen? Davon hängt ab, wie du die Ergebnisse gruppierst. Die Verknüpfung tut nur ihren Job, sie entscheidet nicht für dich, welche Granularität du brauchst.
Integration in moderne Daten-Stacks
Heute arbeiten wir nicht mehr nur auf einer Datenbank. Tools wie dbt oder Cloud-Speicher wie BigQuery nutzen SQL als Standardsprache für Transformationen. Auch dort gelten die exakt gleichen Regeln für die Verknüpfung von Tabellen. In einem Data Warehouse ist es sogar noch wichtiger, die linke Verknüpfung zu beherrschen, weil man dort oft Dimensionstabellen gegen Faktentabellen prüft. Wenn du dort Daten verlierst, stimmen deine gesamten Geschäftsmetriken nicht mehr. Ein Fehler in der SQL-Logik kann so schnell zu falschen Geschäftsentscheidungen führen.
Optimierung und Fehlerdiagnose
Wenn eine Abfrage nicht das liefert, was du erwartest, musst du systematisch vorgehen. Ich fange meistens damit an, die Anzahl der Zeilen der linken Tabelle zu zählen. Danach führe ich die Verknüpfung aus und schaue, ob die Zahl gleich bleibt. Wenn sie sich erhöht, habe ich Duplikate auf der rechten Seite. Wenn sie sinkt, habe ich irgendwo versehentlich einen Inner Join oder einen Filter eingebaut, der Zeilen frisst.
Verwendung von COALESCE für bessere Berichte
Niemand will in einem Bericht für Endanwender das Wort "NULL" lesen. Es wirkt unprofessionell und verwirrend. Mit der Funktion COALESCE kannst du diese Lücken elegant füllen. Statt einer leeren Zelle bei den Verkaufszahlen kannst du eine "0" anzeigen lassen. Oder statt eines leeren Namens schreibst du "Unbekannter Gast". Das macht deine Daten nicht nur technisch korrekt, sondern auch benutzertauglich. Es sind diese kleinen Details in der SQL-Programmierung, die einen Junior von einem Senior unterscheiden.
Die Rolle der Datenbank-Engines
Es gibt feine Unterschiede, wie Datenbanken diese Abfragen intern abarbeiten. Ein PostgreSQL-Server nutzt vielleicht einen Hash-Join, während eine andere Engine auf einen Nested-Loop setzt. Für dich als Entwickler ist das meistens egal, solange die Indizes stimmen. Aber bei extrem großen Datenmengen kann es sinnvoll sein, sich den Ausführungsplan anzuschauen. Jedes moderne SQL-Tool bietet einen Befehl wie EXPLAIN, um zu zeigen, was unter der Haube passiert. Wer das ignoriert, spielt bei der Performance russisches Roulette.
Datenbereinigung vor der Verknüpfung
Oft liegen die Probleme gar nicht im SQL-Code, sondern in der Datenqualität. Unterschiedliche Datentypen oder unsichtbare Leerzeichen in Strings können dazu führen, dass die Verknüpfung fehlschlägt. Ein Kunde mit der ID "123 " (mit Leerzeichen) wird nicht mit der ID "123" in der Bestelltabelle abgeglichen. In solchen Fällen hilft es, Funktionen wie TRIM oder explizite Typkonvertierungen direkt in der On-Klausel zu nutzen. Das kostet zwar etwas Performance, ist aber oft die einzige Möglichkeit, mit unsauberen Datenquellen umzugehen, die man nicht selbst kontrolliert.
Typische Fragen aus der Praxis
Ich werde oft gefragt: Sollte ich diese Verknüpfung immer nutzen, um sicherzugehen? Die Antwort ist ein klares Nein. Wenn du weißt, dass zu jedem Datensatz links zwingend ein Datensatz rechts existieren muss, ist ein Inner Join effizienter und zeigt dir sofort an, wenn etwas mit deiner Datenintegrität nicht stimmt. Die linke Außenseite ist ein Werkzeug für Szenarien, in denen Optionalität herrscht. Man muss lernen, die Semantik der Daten zu verstehen, bevor man den ersten Befehl tippt.
Vergleich mit Subqueries
Manchmal versuchen Leute, Verknüpfungen durch Unterabfragen in der Select-Liste zu umgehen. Das funktioniert zwar oft für einzelne Werte, skaliert aber katastrophal schlecht. Die Datenbank muss dann für jede einzelne Zeile deiner Haupttabelle eine separate kleine Abfrage starten. Bei 10.000 Zeilen sind das 10.000 zusätzliche Abfragen. Eine ordentliche Verknüpfung hingegen wird vom Optimizer als ein einziger Block verarbeitet. Das ist fast immer die bessere Wahl für deine Hardware-Ressourcen.
Umgang mit großen Datenmengen in der Cloud
In Zeiten von Snowflake oder AWS Redshift haben wir es oft mit Datenmengen im Petabyte-Bereich zu tun. Hier ändert sich die Strategie etwas. Da Speicher dort billig und Rechenleistung teuer ist, versucht man oft, Verknüpfungen so weit wie möglich zu vermeiden, indem man Daten denormalisiert. Aber solange wir über relationale Strukturen sprechen, bleibt die Logik der linken Verknüpfung der Goldstandard. Man kann die physikalische Speicherung optimieren, aber die logische Verknüpfung bleibt identisch.
Strategie für fehlerfreie Datenbankabfragen
Wenn du das nächste Mal vor einer leeren Konsole sitzt, gehe methodisch vor. Überlege dir zuerst, welche Tabelle deine "Wahrheit" darstellt – also die Liste, die auf keinen Fall schrumpfen darf. Das ist deine linke Tabelle. Alles andere wird nur angedockt. Teste deine Abfrage immer erst mit einer kleinen Stichprobe, bevor du sie auf den gesamten Datensatz loslässt. So vermeidest du Endlosschleifen oder Speicherüberläufe, die das gesamte System lahmlegen könnten.
Dokumentation und Lesbarkeit
Schreibe deinen Code für Menschen, nicht nur für Maschinen. Nutze Aliase für deine Tabellen, die Sinn ergeben. Statt a und b nimm lieber kunden und bestellungen. Das hilft ungemein, wenn du nach sechs Monaten wieder in den Code schauen musst oder ein Kollege deine Abfrage übernehmen soll. Eine gut strukturierte SQL-Abfrage ist wie eine gute Geschichte: Man versteht sofort, wer die Hauptfigur ist und welche Nebeninformationen dazukommen.
Zusammenfassung der nächsten Schritte
Jetzt ist es an der Zeit, das Wissen anzuwenden. Du musst nicht warten, bis das nächste große Projekt ansteht.
- Schnapp dir eine Testdatenbank und baue zwei Tabellen mit bewussten Lücken.
- Experimentiere mit Filtern in der On-Klausel und beobachte, wie sich die Ergebnismenge verändert.
- Nutze
EXPLAIN, um zu sehen, wie die Datenbank deine Abfrage intern plant. - Prüfe deine bestehenden Berichte: Gibt es dort Inner Joins, die eigentlich linke Außenseiten sein müssten? Oft finden sich hier die Fehler, die schon seit Monaten unentdeckt geblieben sind.
- Implementiere
COALESCE, um deine Berichte für die Endnutzer sauberer zu gestalten.
Datenanalyse ist Handwerk. Je öfter du diese Werkzeuge benutzt, desto intuitiver werden sie. Es gibt keine Abkürzung zur Meisterschaft, nur viele geschriebene Zeilen Code und die Analyse der Fehler, die dabei zwangsläufig passieren. Vertraue auf die Logik der relationalen Algebra, aber behalte immer die Realität deiner Daten im Blick. Wer die Nuancen der Tabellenverknüpfung versteht, hat die volle Kontrolle über seine Informationen und kann fundierte Aussagen treffen, die auf Fakten basieren, statt auf Lücken, die man versehentlich weggefiltert hat.



