Wer jemals vor einem Berg an Umfragedaten saß und wissen wollte, ob der Zusammenhang zwischen zwei Variablen bloßer Zufall oder harte Realität ist, kommt an einem Werkzeug nicht vorbei. Ich spreche von der Tabelle Der Chi Quadrat Verteilung, die in der Statistik oft wie ein Relikt aus dem Analogzeitalter wirkt, aber nach wie vor das Rückgrat für Signifikanztests bildet. Man schaut nicht einfach nur auf bunte Diagramme. Man prüft, ob die Abweichungen zwischen dem, was man beobachtet hat, und dem, was man theoretisch erwartet hätte, groß genug sind, um eine Hypothese über Bord zu werfen. Das klingt trocken. Ist es aber nicht, wenn man bedenkt, dass Marketingentscheidungen in Millionenhöhe oder medizinische Studien genau auf diesen Werten basieren.
Die Logik hinter dem Chi-Quadrat-Test
Bevor man blind Zahlen in eine Formel wirft, sollte man begreifen, was man da eigentlich tut. Der Test misst die Diskrepanz. Stell dir vor, du würfelst 60 Mal. Theoretisch erwartest du, dass jede Zahl zehnmal erscheint. In der Realität kommt die Sechs vielleicht 15 Mal vor. Ist der Würfel gezinkt? Oder ist das normales Rauschen? Hier kommt die Mathematik ins Spiel.
Nullhypothese und Alternativhypothese
Jeder statistische Test beginnt mit der Annahme, dass es keinen Effekt gibt. Das nennen wir die Nullhypothese. Ich gehe also erst einmal davon aus, dass mein Würfel fair ist. Die Alternativhypothese besagt das Gegenteil: Da stimmt was nicht. Um das zu beweisen, berechnen wir eine Prüfgröße. Diese folgt einer ganz bestimmten mathematischen Kurve, die Karl Pearson bereits um 1900 prägte.
Freiheitsgrade einfach erklärt
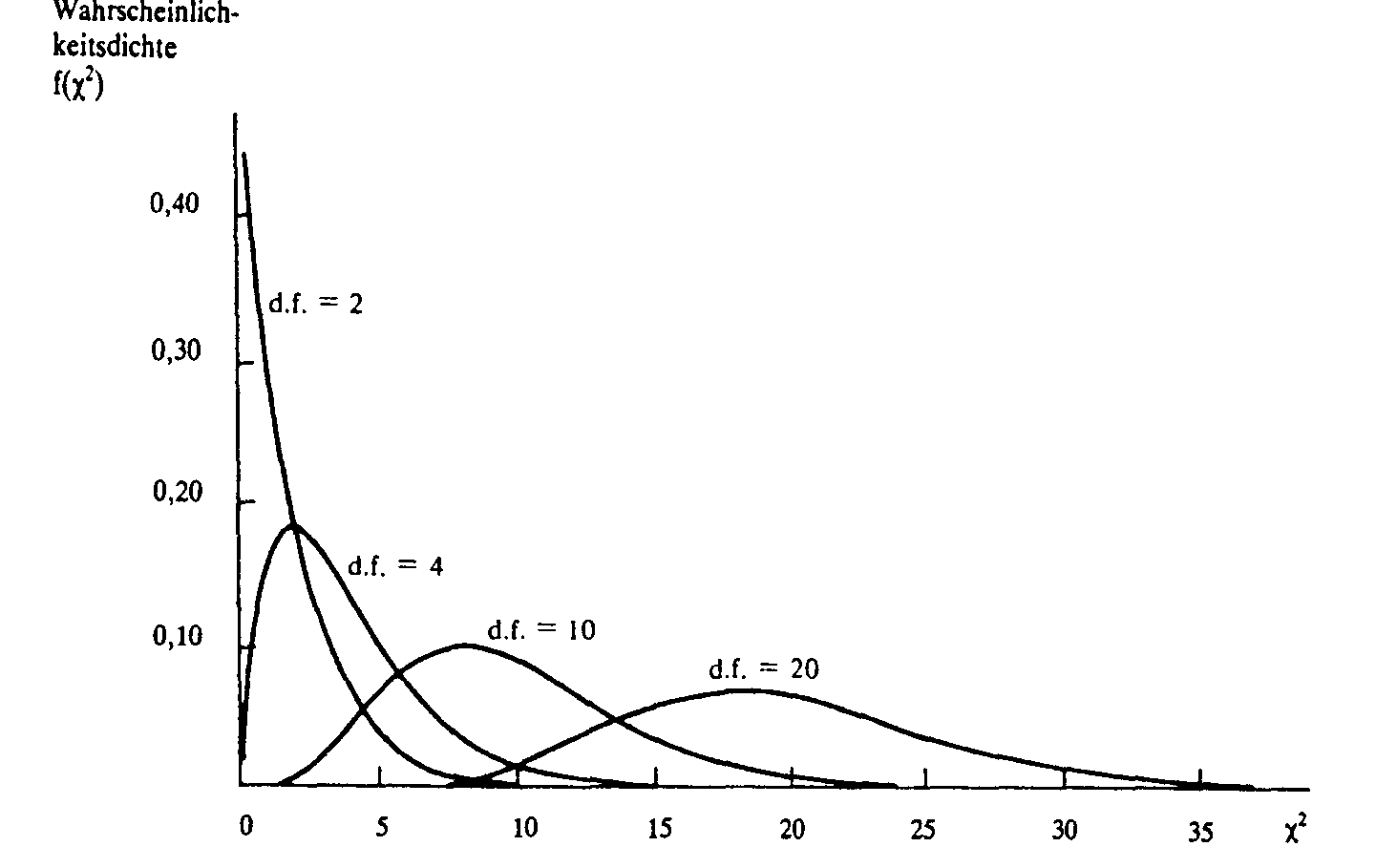
Ein Begriff, der Anfänger regelmäßig in den Wahnsinn treibt, sind die Freiheitsgrade. Ich erkläre es meinen Studenten immer so: Wenn du sieben Hüte für sieben Tage hast, kannst du an den ersten sechs Tagen frei wählen. Am siebten Tag hast du keine Wahl mehr. Der letzte Hut ist festgelegt. In einer Kontingenztabelle mit Zeilen und Spalten berechnet man das über $(r-1) \times (c-1)$. Wenn du das falsch machst, ist dein gesamtes Ergebnis wertlos. Die Kurve der Verteilung verändert ihre Form massiv, je nachdem, wie viele Freiheitsgrade im Spiel sind. Bei wenigen Freiheitsgraden ist sie stark rechtsschief. Bei vielen Freiheitsgraden nähert sie sich fast einer Normalverteilung an.
Tabelle Der Chi Quadrat Verteilung richtig lesen und anwenden
Man braucht kein Informatikstudium, um diese Werte zu interpretieren, aber man braucht Präzision. In der ersten Spalte suchst du deine Freiheitsgrade. In der obersten Zeile steht das Signifikanzniveau, meistens mit dem griechischen Buchstaben Alpha bezeichnet. Wenn du ein Alpha von 0,05 wählst, akzeptierst du ein Risiko von fünf Prozent, dass du einen Effekt siehst, der gar nicht da ist.
Der kritische Wert als Grenzpfosten
In der Praxis suchst du den Schnittpunkt. Dieser Wert ist dein Grenzpfosten. Ist dein berechneter Wert größer als dieser kritische Wert aus der Liste? Dann herzlichen Glückwunsch, dein Ergebnis ist statistisch signifikant. Du kannst die Nullhypothese ablehnen. Bleibt dein Wert darunter, musst du akzeptieren, dass deine Beobachtungen wahrscheinlich nur Zufall waren. Das ist oft frustrierend, aber so funktioniert ehrliche Wissenschaft. Wer hier schummelt, betreibt "p-Hacking", ein riesiges Problem in der modernen Forschung.
Typische Fehler beim Ablesen
Oft verwechseln Leute die einseitige und zweiseitige Fragestellung. Beim Chi-Quadrat-Test für Unabhängigkeit schauen wir uns fast immer das rechte Ende der Verteilung an. Wir wollen wissen, ob die Abweichung extrem nach oben ausschlägt. Ein weiterer Patzer ist die Stichprobengröße. Wenn in einer Zelle deiner Erwartungstabelle weniger als fünf Beobachtungen stehen, wird der Test ungenau. In solchen Fällen greift man besser zum exakten Test nach Fisher. Das ist zwar rechenintensiver, aber am Ende des Tages zählt die Validität deiner Aussage.
Praktische Anwendung in der Marktforschung
Nehmen wir ein reales Szenario. Ein E-Commerce-Unternehmen aus Berlin möchte wissen, ob das Geschlecht der Kunden die Wahl der Zahlungsmethode beeinflusst. Sie sammeln Daten von 500 Transaktionen. Es gibt die Kategorien "Rechnung", "Kreditkarte" und "PayPal". Ohne statistische Prüfung sieht es vielleicht so aus, als würden Frauen eher auf Rechnung kaufen. Aber ist dieser Unterschied groß genug, um die gesamte Marketingstrategie darauf auszurichten?
Hier berechnet man die erwarteten Häufigkeiten unter der Annahme, dass es absolut keinen Unterschied gibt. Man summiert die quadrierten Differenzen, teilt sie durch die Erwartungswerte und erhält eine Zahl. Dann zückt man das Referenzblatt. Wenn der berechnete Wert bei zwei Freiheitsgraden über 5,99 liegt (für ein 5-Prozent-Niveau), dann ist die Sache klar. Es gibt einen Zusammenhang. Das Unternehmen sollte also geschlechtsspezifische Bezahloptionen priorisieren.
Warum Quadrieren so wichtig ist
Vielleicht fragst du dich, warum wir die Differenzen überhaupt quadrieren. Würden wir das nicht tun, würden sich positive und negative Abweichungen einfach gegenseitig aufheben. Das Ergebnis wäre null. Durch das Quadrieren werden alle Abweichungen positiv. Große Ausreißer werden zudem stärker gewichtet. Das gibt dem Test seine Schärfe. Es bestraft quasi starke Unstimmigkeiten zwischen Theorie und Praxis.
Mathematische Grundlagen und Voraussetzungen
Man darf diesen Test nicht auf alles werfen, was nicht bei drei auf den Bäumen ist. Die Daten müssen nominal- oder ordinalskaliert sein. Das bedeutet Kategorien wie "Ja/Nein", "Farben" oder "Bildungsabschlüsse". Für metrische Daten wie Körpergröße oder Einkommen gibt es andere Verfahren. Wer hier das falsche Skalenniveau wählt, produziert Datenmüll.
Eine weitere harte Bedingung ist die Unabhängigkeit der Beobachtungen. Du kannst nicht denselben Kunden zweimal befragen und so tun, als wären es zwei verschiedene Personen. Das würde die Varianz künstlich verkleinern und das Ergebnis verfälschen. In der psychologischen Forschung an Universitäten wie der Ludwig-Maximilians-Universität München wird peinlich genau darauf geachtet, dass Versuchsdesigns diese Unabhängigkeit wahren.
Die Bedeutung von Alpha und Beta
Statistik ist immer ein Spiel mit Wahrscheinlichkeiten. Wenn du dein Alpha-Niveau auf 0,01 setzt, bist du sehr streng. Du willst dir fast absolut sicher sein. Aber Vorsicht: Je kleiner Alpha ist, desto größer wird das Risiko eines Beta-Fehlers. Das bedeutet, du übersiehst einen echten Effekt, weil deine Hürde zu hoch war. In der Medizin, etwa bei der Zulassung neuer Medikamente durch das Bundesinstitut für Arzneimittel und Medizinprodukte, ist diese Abwägung eine Frage von Leben und Tod. Ein zu lockeres Alpha lässt unwirksame Mittel zu. Ein zu strenges verhindert vielleicht eine Heilung.
Vergleich mit anderen Verteilungen
Oft wird gefragt, warum man nicht einfach die Normalverteilung nutzt. Die Antwort liegt in der Natur der Daten. Die Summe von quadrierten, standardnormalverteilten Zufallsvariablen folgt eben genau der Chi-Quadrat-Struktur. Sie ist sozusagen eine abgeleitete Form. Wenn du nur eine einzige Stichprobe gegen einen bekannten Wert prüfst, nutzt du den Anpassungstest. Willst du zwei Merkmale vergleichen, ist es der Unabhängigkeitstest. Es gibt auch noch den Homogenitätstest, bei dem man prüft, ob zwei verschiedene Populationen die gleiche Verteilung hinsichtlich eines Merkmals aufweisen.
Interpretation der Ergebnisse in der Software
Heutzutage rechnet kaum noch jemand mit dem Taschenrechner. Programme wie SPSS, R oder Python-Bibliotheken wie SciPy erledigen das in Millisekunden. Aber was sie ausgeben, ist oft nur ein p-Wert. Dieser p-Wert ist das Pendant zur Tabelle Der Chi Quadrat Verteilung. Er sagt dir, wie wahrscheinlich es ist, deine Daten zu erhalten, wenn die Nullhypothese wahr wäre. Ist p kleiner als 0,05, hast du deinen Treffer.
Ich habe oft erlebt, dass Leute blind auf diesen p-Wert starren, ohne die Effektstärke zu prüfen. Ein Ergebnis kann signifikant sein, aber in der realen Welt völlig unbedeutend. Wenn du 100.000 Menschen befragst, wird fast jeder winzige Unterschied signifikant. Deshalb berechnet man zusätzlich Maße wie Cramérs V oder den Phi-Koeffizienten. Diese sagen dir, wie stark der Zusammenhang wirklich ist. Ein signifikanter Test ohne nennenswerte Effektstärke ist meistens nur heiße Luft.
Der Einfluss der Stichprobengröße
Große Stichproben sind ein zweischneidiges Schwert. Sie erhöhen die Power des Tests. Das ist gut. Man findet kleine Effekte eher. Aber sie führen auch dazu, dass triviale Unterschiede wichtig erscheinen. Stell dir vor, du findest heraus, dass Linkshänder 0,1 % häufiger grüne Autos kaufen als Rechtshänder. Bei einer Million Befragten ist das hochgradig signifikant. Aber ist es für einen Autohändler relevant? Absolut nicht. Hier muss der gesunde Menschenverstand über die reine Mathematik siegen.
Validierung durch Kreuztabellen
Bevor man den Wert interpretiert, muss man einen Blick in die Kreuztabelle werfen. Schau dir die Zellen an. Wo liegen die größten Abweichungen? Der Test gibt dir nur eine globale Antwort: "Ja, da ist was." Er sagt dir nicht, welche spezifische Gruppe für den Effekt verantwortlich ist. Dafür musst du die Residuen analysieren. Standardisierte Residuen über einem Wert von 2 oder unter -2 zeigen dir genau, wo der Hase im Pfeffer liegt.
Herausforderungen in der modernen Datenwissenschaft
In Zeiten von Big Data wird der klassische Test oft kritisiert. Er stammt aus einer Ära, in der Daten teuer und selten waren. Heute haben wir Terabytes davon. Dennoch bleibt das Prinzip der Verteilung fundamental. Sogar in komplexen Modellen des maschinellen Lernens werden ähnliche Logiken genutzt, um die Güte eines Modells zu bewerten. Man vergleicht das Modell mit einem Basismodell und schaut, ob die Verbesserung signifikant ist.
Grenzen der Methode
Man darf nicht vergessen, dass Korrelation keine Kausalität ist. Nur weil der Chi-Quadrat-Test einen Zusammenhang zwischen dem Konsum von Speiseeis und Sonnenbränden bestätigt, verursacht das Eis nicht den Brand. Beide hängen von der Sonne ab. Das ist ein Anfängerfehler, den man immer wieder sieht. Statistik liefert Indizien, keine Beweise für Ursache und Wirkung. Wer das ignoriert, zieht falsche Schlüsse, die im Business teuer werden können.
Software-Tipps für die Praxis
Wenn du mit R arbeitest, ist der Befehl chisq.test() dein bester Freund. Er liefert dir nicht nur den Prüfwert, sondern warnt dich auch, wenn die Voraussetzungen verletzt sind. In Python nutzt man scipy.stats.chi2_contingency. Diese Tools sind mächtig, aber sie entbinden dich nicht von der Pflicht, die Theorie dahinter zu kennen. Ein Tool ist nur so gut wie die Person, die es bedient.
Nächste Schritte für deine Analyse
Wenn du jetzt vor deinen Daten sitzt, solltest du systematisch vorgehen. Erstens: Prüfe dein Skalenniveau. Sind es wirklich Kategorien? Zweitens: Erstelle eine Kontingenztabelle. Drittens: Berechne die erwarteten Werte. Wenn diese alle über fünf liegen, kannst du loslegen.
- Wähle dein Signifikanzniveau. Im Zweifelsfall nimm 0,05.
- Bestimme die Freiheitsgrade basierend auf der Größe deiner Tabelle.
- Berechne den Chi-Quadrat-Wert manuell oder per Software.
- Vergleiche das Ergebnis mit dem kritischen Wert oder prüfe den p-Wert.
- Berechne unbedingt eine Effektstärke wie Cramérs V, um die Relevanz zu bewerten.
- Schau dir die Residuen an, um zu verstehen, welche Gruppen den Unterschied machen.
Statistik ist kein Voodoo. Es ist ein Handwerk. Wer die Werkzeuge beherrscht, kann Geschichten aus Daten lesen, die anderen verborgen bleiben. Es geht darum, Muster im Chaos zu finden und fundierte Entscheidungen zu treffen. Ob in der Forschung an der Charité Berlin oder in der Optimierung eines Onlineshops – die Prinzipien bleiben gleich. Nutze sie weise und lass dich nicht von großen Zahlen blenden. Am Ende zählt die Qualität der Fragestellung und die Genauigkeit der Ausführung.



